De nombreuses disciplines scientifiques reposent sur l’étude de structures permettant de décrire des transformations et des interactions entre objets. En chimie, les symétries moléculaires jouent un rôle essentiel dans la compréhension des propriétés des composés ; en géométrie, les transformations permettent de caractériser les figures indépendamment de leur position ; en infographie, ces mêmes transformations sont utilisées pour manipuler et animer des objets. Dans chacun de ces contextes, il ne s’agit pas seulement d’objets, mais d’actions que l’on peut composer et inverser.
Les structures algébriques fournissent un cadre abstrait pour formaliser ces situations : on considère un ensemble d’objets muni d’une opération qui permet de les combiner. Selon les propriétés vérifiées par cette opération, on obtient différents niveaux de structure, qui permettent de raisonner de manière uniforme sur des systèmes très variés. Cette approche met l’accent non pas sur la nature des objets, mais sur les règles de manipulation qui les gouvernent.
En informatique, ce point de vue est omniprésent. De nombreux objets peuvent être vus comme des transformations que l’on compose : fonctions, programmes, opérations sur des données. Par exemple, la composition de fonctions est au cœur de la programmation ; la concaténation de mots intervient en théorie des langages ; les transformations géométriques sont utilisées en infographie ; et les permutations d’un ensemble jouent un rôle fondamental dans l’analyse des algorithmes, notamment dans les problèmes de tri.
Les structures de type groupe apparaissent dès que l’on manipule des transformations réversibles. Elles permettent de modéliser des situations où une opération peut être annulée, et où des séquences d’actions peuvent être simplifiées ou réorganisées. Ce cadre est particulièrement adapté à l’étude des symétries, mais aussi à des problèmes plus algorithmiques, où l’on cherche à transformer une configuration initiale en une configuration cible par une suite d’opérations élémentaires.
Reconnaître une telle structure permet de disposer immédiatement d’un ensemble de propriétés générales, indépendantes du contexte particulier. Ces structures jouent ainsi un rôle unificateur en informatique : elles permettent de décrire, d’analyser et d’optimiser des processus de transformation, qui sont au cœur de nombreux algorithmes et systèmes.
Le taquin
Le jeu du taquin est un casse-tête solitaire inventé par Sam Loyd aux États-Unis à la fin du 19ème siècle. Il se présente sous la forme d'un plateau carré subdivisé en \(4\times 4=16\) cases occupées par \(15\) pièces carrées numérotées de \(1\) à \(15\) (cf. figure ci-dessous). Une pièce adjacente à la case vide peut y coulisser : la pièce 12 ou la pièce 14 peuvent coulisser vers la case vide 16 dans la configuration proposée par Loyd :
Le but du jeu est de ranger les 15 pièces dans l'ordre croissant de \(1\) à \(15\) en les faisant coulisser le long des lignes et des colonnes. Sam Loyd proposa la somme de $1.000 au premier qui trouverait une solution. Vous pouvez essayer vous-même avec le simulateur ci-dessus : cliquez sur une pièce qui est sur la même ligne ou la même colonne que la case vide, elle pousse toutes les pièces vers la case vide.
Ce jeu a été décliné de très nombreuses façons, par exemple en remplaçant les nombres par des portions d'une image à reconstituer à la manière d'un puzzle. Le célèbre Rubik's Cube est en quelque sorte une extension à trois dimensions de ce problème. L'objectif de ce chapitre est de comprendre pourquoi Sam Loyd ne risquait pas de perdre ses $1.000 et de trouver comment résoudre d'autres configurations, quand elles admettent une solution.
Question :
Comment ranger les 15 pièces du taquin dans l'ordre croissant ?
Nous avons étudié aux chapitres précédents, les ensembles puis les relations qui pouvaient les lier et leur cardinalité. Nous allons à présent les animer en les équipant de quelques rouages.
Lois de composition et structures
Il s'agit d'observer le fonctionnement des opérations bien connues sur les nombres (addition, multiplication, etc.) et de les généraliser à des ensembles quelconques. On cherche donc à déterminer les propriétés qu'elles partagent plutôt que leurs particularités, et d'en tirer des résultats universels susceptibles d'être appliqués à toutes sortes de situations.
Loi de composition interne, magma
Que ce soit l'addition et la multiplication définies sur les entiers naturels ou encore la réunion et l'intersection définies sur les parties d'un ensemble, ces opérations ont pour premier point commun de composer deux éléments d'un ensemble de référence pour obtenir un élément de ce même ensemble :
On appelle loi de composition interne sur un ensemble \(X\) toute application \(\diamond\) de \(X\times X\) dans \(X\). Dans ce cas le couple \((X,\diamond)\) est appelé un magma.
Le composé de deux éléments \(x\) et \(y\) de \(X\) par la loi \(\diamond\) est noté de manière infixe \(x\;{\color{#FF8}\diamond}\;y\) plutôt que de manière préfixe \({\color{#88F}\,\diamond}\,(x,y)\) comme c'est généralement l'usage pour une application. La notation postfixe \((x,y)\,{\color{#8F8}\diamond}\), assez peu usitée dans les écritures mathématiques, s'avère pourtant particulièrement adaptée pour réaliser des calculs effectifs, comme on le verra en algorithmique.
Dans tout le chapitre un couple \((X,\diamond)\) désigne un magma.
(1) L'addition et la multiplication définies sur l'ensemble des entiers naturels \(\N\) au chapitre Combinatoire sont donc des lois de composition internes faisant de \((\N,+)\) et \((\N,\times)\) deux magmas.
(2) La réunion \(\cup\) et l'intersection \(\cap\) sur \({\mathscr P}(X)\) l'ensemble des parties d'un ensemble \(X\) sont des lois de composition internes faisant de \(({\mathscr P}(X),\cup)\) et \(({\mathscr P}(X),\cap)\) deux magmas.
(3)
La composition des applications \(\circ\) d'un ensemble \(X\) dans lui-même, définit une loi de composition interne sur \(X^X\) faisant de \((X^X,\circ)\) un magma.
(4) La concaténation \(\cdot\) est une loi de composition interne sur l'ensemble \(\Sigma^*\) des mots définis sur un alphabet fini \(\Sigma\) faisant de \((\Sigma^+,\cdot)\) un magma.
Le couple \((X,\diamond)\) où \(X:=\{a,b\}\) et \(\diamond\) est définie par
\[
a\diamond a=a,\ \ a\diamond b=b,\ \ b\diamond a=b\ \ \text{et}\ \ b\diamond b=a
\]
est-il un magma ? Justifiez.
Les images de tous les couples de \(X^2\) sont bien des éléments de \(X,\) la loi est donc interne.
Le couple \((\mathscr{A},\cdot)\) où \(\mathscr{A}:=\{a,b,\ldots,z\}\) est l'alphabet latin et \(\cdot\) est la loi de concaténation, forme-t-il un magma sur \(\mathscr{A}\) ? Justifiez.
La concaténation de deux symboles de \(\mathscr{A}\) ne forme pas un symbole de \(\mathscr{A},\) la concaténation définie sur \(\mathscr{A}\) n'est donc pas une loi de composition interne. Elle l'est en revanche sur l'ensemble \(\mathscr{A}^*\) des mots définis sur l'alphabet \(\mathscr{A},\) en effet la concaténation de deux mots forme bien un mot.
Partie stable
Une partie \(A\) de \(X\) est dite stable pour la loi \(\diamond\) si et seulement si tous les composés d'éléments de \(A\) sont eux aussi des éléments de \(A\) :
\begin{equation}
\forall (x,y)\in A \times A\quad x\diamond y \in A.
\end{equation}
Dans ce cas, la restriction de la loi de composition \(\diamond\) aux éléments de \(A\times A\) est une loi de composition interne sur \(A\), appelée loi induite par \(\diamond\) sur \(A\), et on conserve la même notation pour le magma \((A,\diamond)\).
(1) L'ensemble \(2\,\N\) des entiers pairs est une partie stable pour la loi d'addition \(+\) sur l'ensemble des entiers naturels \(\N\) faisant de \((2\,\N,+)\) un magma.
(2) L'ensemble \(S(X)\) des bijections d'un ensemble \(X\) sur lui-même est une partie stable de \(X^X\) pour la loi de composition des applications \(\circ\).
Montrez que l'ensemble des entiers impairs de \(\Z\) est stable pour la multiplication mais pas pour l'addition.
Considérons \(a\) et \(b\) deux entiers impairs quelconques. Il existe donc deux entiers \(k_a\) et \(k_b\) tels que \(a=2k_a+1\) et \(b=2k_b+1.\) Ainsi
\begin{align*}
a\cdot b&=(2k_a+1)(2k_b+1)\\
&=4k_ak_b+2k_a+2k_b+1\\
&=2(2k_ak_b+k_a+k_b)+1
\end{align*}
Donc l'entier \(a\cdot b\) est impair, ce qui prouve que l'ensemble des entiers impairs est stable pour la multiplication. En revanche
\begin{align*}
a+b&=(2k_a+1)+(2k_b+1)\\
&=2k_a+2k_b+2\\
&=2(k_a+k_b+1)
\end{align*}
Donc l'entier \(a+b\) est pair, ce qui prouve que l'ensemble des entiers impairs n'est pas stable pour l'addition.
Soit \(X:=\{0,1,2,3\}\) muni de la loi \(\diamond\) définie par \(a\diamond b:=\min\{a+b,2\}.\) Montrez que la partie \(A:=\{1,2\}\) est stable pour la loi \(\diamond.\)
Il suffit de composer tous les éléments de \(A\) entre eux et de vérifier que le résultat reste dans \(A\) :
\begin{align*}
1\diamond 1&=1 &
1\diamond 2&=1 & 2\diamond 1&=1 &
2\diamond 2&=2
\end{align*}
Associativité
Une loi de composition interne \(\diamond\) est dite associative si et seulement si
\begin{equation}
\forall (x,y,z)\in X^3\quad x\diamond(y\diamond z)= (x\diamond y)\diamond z.
\end{equation}
Dans ce cas le magma est dit associatif.
(1) L'addition et de la multiplication sur les entiers naturels sont deux lois associatives, c'est cette propriété qui nous permet de nous affranchir des parenthèses dans l'expression \(x+y+z\) et l'expression \(x\times y\times z\). Ces expressions n'auraient pas de sens si ces lois n'étaient pas associatives.
(2) Le magma \((X^X,\circ)\) est associatif (cf. exercice). La loi puissance est bien une loi de composition interne sur \(\N\), mais n'est pas associative, par exemple \(2^{(2^3)}=256\) alors que \((2^2)^3=64\).
Vérifiez que la soustraction n'est pas associative dans \(\Z\).
Voilà un contre-exemple immédiat : \(3-(2-1)=2\) mais \((3-2)-1=0.\)
Modélisez le jeu pierre, feuille, ciseaux comme une loi de composition sur l'ensemble \(\{p,f,c\},\) le résultat de la composition étant le vainqueur de l'épreuve. Vérifiez que cette loi n'est pas associative.
L'ensemble étant de cardinal \(3,\) il y a \(9\) couples à considérer pour définir la loi de composition \(\diamond\) :
\begin{align*}
p\diamond p&=p & p\diamond f&=f & p\diamond c&=p\\
f\diamond p&=f & f\diamond f&=f & f\diamond c&=c\\
c\diamond p&=p & c\diamond f&=c & c\diamond c&=c
\end{align*}
Elle n'est pas associative, en effet \((p\diamond f)\diamond c=f\diamond c={\color{red}c}\) mais \(p\diamond (f\diamond c)=p\diamond c={\color{red}p}.\)
Commutativité
On dit que deux éléments \(x\) et \(y\) de \(X\) commutent si et seulement si
\begin{equation}
x\diamond y = y \diamond x.
\end{equation}
On appelle centre d'un magma, le sous-ensemble \(Z_X\) des éléments de \(X\) qui commutent avec n'importe quel élément de \(X\) :
\begin{equation}
Z_X:=\{z\in X\such\forall x\in X\ \ z\diamond x=x\diamond z\}.
\end{equation}
Si \(Z_X=X\), autrement dit si tous les éléments de \(X\) commutent, le magma est dit commutatif.
(1) Le magma \((\N,+)\) est commutatif.
(2) Le magma \((\R,\times)\) est commutatif.
(3) Pour tout ensemble \(X\), les magmas \((\mathscr{P}(X),\cup)\) et \((\mathscr{P}(X),\cap)\) sont commutatifs.
Soit \(X\) un ensemble. Montrez que la loi de composition des applications \(\circ\) n'est pas commutative en général pour le magma \((X^X,\circ).\)
Considérons \(X:=\N\) et les applications \(f:\N\to\N\) et \(g:\N\to\N\) définies par \(f(n):= n+1\) et \(g(n):= 2n.\) Alors pour tout \(n\in\N\) :
\begin{align*}
(f\circ g)(n)&=f(g(n)) & (g\circ f)(n) &=g(f(n)) \\
&=f(2n) & &=g(n+1)\\
&=2n + 1 & &=2(n+1)
\end{align*}
donc \(g\circ f\neq f\circ g\).
Montrez que la loi de concaténation \(\cdot\) sur l'ensemble des mots définis sur un alphabet \(\mathscr{A}\) de plus de deux symboles n'est pas commutative.
Par hypothèse, on sait qu'il existe au moins deux symboles distincts \(x\) et \(y\) dans \(\mathscr{A}.\) Ainsi \(x.y=xy\) et \(y.x=yx,\) et les mots \(xy\) et \(yx\) sont différents.
Élément neutre
On appelle élément neutre pour la loi \(\diamond\) tout élément \(e\in X\) tel que
\begin{equation}
\label{eq:egelemneutre}
\forall x\in X\quad x\diamond e = e \diamond x=x.
\end{equation}
S'il existe un élément neutre, celui-ci est nécessairement unique. Un magma dont la loi possède un élément neutre est dit unifère.
(1) L'entier naturel \(0\) est l'élément neutre pour l'addition dans \(\N.\)
(2) Le réel \(1\) est l'élément neutre pour la multiplication dans \(\R\).
(3) L'ensemble \(X\) est l'élément neutre pour le magma \(({\mathscr P}(X),\cap).\)
(4) Le magma \((X^X,\circ)\) est unifère d'élément neutre l'application identique \({\Id}_X\).
Quel est l'élément neutre pour la loi de concaténation sur les mots définis sur un alphabet \(\mathscr{A}\) ?
Il s'agit du mot vide noté \(\varepsilon\) qui est le pendant mathématique de la chaîne vide "" du Python.
Quel est l'élément neutre pour la loi de concaténation sur les mots définis sur un alphabet \(\mathscr{A}\) ?
Il s'agit du mot vide noté \(\varepsilon\) qui est le pendant mathématique de la chaîne vide "" du Python.
Soit \(X\) un ensemble. Quel est l'élément neutre pour le magma \(({\mathscr P}(X),\cup)\) ?
Il s'agit bien sûr de l'ensemble vide \(\varnothing\) puisque
\[\forall Y\in{\mathscr P}(X)\quad Y\cup\varnothing=\varnothing\cup Y=Y.\]
Démontrez qu'un élément neutre d'un magma unifère est nécessairement unique.
Par l'absurde, supposons qu'il existe deux éléments neutres \(e\) et \(e'\). On applique \((\ref{eq:egelemneutre})\) pour l'élément neutre \(e\) avec \(x:=e'\) puis pour l'élément neutre \(e'\) avec \(x:=e\) pour obtenir respectivement :
\begin{align*}
e'\diamond e &= e\diamond e' = e'\\
e\diamond e' &= e'\diamond e = e
\end{align*}
et par transitivité de l'égalité, on en déduit \(e=e'\).
Distributivité
Si un ensemble \(X\) est muni de deux lois de composition internes \(\star\) et \(\diamond\), on dit que \(\star\) est distributive à gauche (resp. distributive à droite) sur \(\diamond\) si et seulement si
\begin{align}
\forall (x,y,z)\in X^3\ \ x\star(y\diamond z) &= (x\star y)\diamond(x\star z),\\
\text{resp.}\ \ \forall (x,y,z)\in X^3\ \ (x\diamond y)\star z &= (x\star z)\diamond(y\star z).
\end{align}
Si la loi est à la fois distributive à gauche et à droite, on dit simplement qu'elle est distributive.
(1) La multiplication est distributive sur l'addition, à gauche et à droite dans \(\Z.\)
(2) L'intersection \(\cap\) est distributive sur la réunion \(\cup\) dans l'ensemble \({\mathscr P}(X)\) des parties d'un ensemble \(X\) et réciproquement :
\begin{align*}
\forall (A,B,C)\in{\mathscr P}(X)^3\quad A\cap(B\cup C)&=(A\cap B)\cup(A\cap C),\\
\forall (A,B,C)\in{\mathscr P}(X)^3\quad A\cup(B\cap C)&=(A\cup B)\cap(A\cup C).
\end{align*}
Démontrez que l'addition n'est pas distributive sur la multiplication dans \(\Z.\)
On a \(2+(3\times 2)\neq (2+3)\times(2+2).\)
Démontrez que l'intersection est distributive sur la réunion et réciproquement sur l'ensemble \({\mathscr P}(X)\) des parties d'un ensemble \(X\).
C'est la conséquence directe de la distributivité du connecteur logique de conjonction sur le connecteur logique de disjonction (et réciproquement). Nous ne montrerons que la distributivité de \(\cap\) sur \(\cup\), la preuve de la distributivité de \(\cup\) sur \(\cap\) étant similaire. Montrons que
\[\forall x\quad x\in A\cap(B\cup C)\iff x\in(A\cap B)\cup(A\cap C).\]
On a
\begin{align*}
x\in A\cap(B\cup C) &\ \iff\ (x\in A)\wedge (x\in (B\cup C))\\
&\ \iff\ (x\in A)\wedge \big((x\in B)\vee (x\in C)\big)\\
&\ \iff\ \big((x\in A)\wedge (x\in B)\big) \vee\big((x\in A)\wedge (x\in C)\big)\\
&\ \iff\ (x\in A\cap B)\vee(x\in A\cap C)\\
&\ \iff\ x\in (A\cap B)\cup (A\cap C)
\end{align*}
Éléments réguliers
Quand on doit résoudre une équation sur un magma \((X,\diamond)\), il est parfois possible de la simplifier en éliminant certains de ses termes : on appelle élément régulier (ou simplifiable) à gauche (resp. élément régulier (ou simplifiable) à droite) tout élément \(r\in X\) tel que
\begin{align*}
\forall (x,y)\in X\times X\quad \underbrace{r\diamond x=r\diamond y}_{\text{équation}}\ \overset{\text{simplif.}}{\Longrightarrow}\ x=y\quad
(\text{resp.}\ \ x\diamond r&=y\diamond r\ \Rightarrow\ x=y),
\end{align*}
Ceci exprime que l'on est en mesure de simplifier l'équation à gauche et/ou à droite par un élément régulier à gauche et/ou à droite.
Un élément qui est la fois régulier à gauche et à droite est dit régulier ou simplifiable.
(1) L'élément neutre pour une loi de composition interne quelconque est nécessairement régulier.
(2) Tout entier naturel est régulier pour l'addition et régulier pour la multiplication.
(3) Dans \({\mathscr P}(X),\) le seul élément régulier pour l'intersection est l'élément neutre \(X\).
Considérons la loi \(\diamond\) définie sur \(\Z\) par \(x\diamond y:=x+y-xy.\) Vérifiez que \(1\) est le seul entier relatif qui n'est pas régulier pour cette loi.
Si \(x\diamond y = x\diamond z\) on a
\begin{align*}
x+y-xy&=x+z-xz\\
y(1-x)=z(1-x)
\end{align*}
Ce qui nous donne \(y=z\) à la condition que \(x\neq 1\).
Éléments symétrisables
Dans le même esprit et avec un outillage un peu plus évolué, il est possible de simplifier des équations plus facilement qu'avec des éléments réguliers. Soit \((X,\diamond)\) un magma unifère d'élément neutre \(e.\) On dit que \(x\in X\) est symétrisable à gauche (resp. symétrisable à droite) s'il existe (au moins) un élément \(x'\in X\) tel que
\begin{align*}
x'\diamond x=e\quad (\text{resp.}\ \ x\diamond x'&=e)
\end{align*}
On dit alors que \(x'\) est un symétrique à gauche (resp. symétrique à droite) de \(x\). On dit que \(x\) est symétrisable s'il est à la fois symétrisable à gauche et à droite.
La notation usuelle pour désigner le symétrique d'un élément symétrisable \(x\) est \(x^{-1},\) en référence aux lois multiplicatives.
Démontrez que tout élément symétrisable d'un magma unifère et associatif est régulier.
Soit \(r\), \(x\) et \(y\) des éléments d'un magma \((X,\diamond)\) et \(r^{-1}\) le symétrique de \(r.\) Si \(r\diamond x= r\diamond y,\) alors :
\begin{align*}
r^{-1}\diamond(r\diamond x)&= r^{-1}\diamond(r\diamond y)\\
(r^{-1}\diamond r)\diamond x&= (r^{-1}\diamond r)\diamond y\\
e\diamond x&= e\diamond y\\
x&= y
\end{align*}
ce qui prouve que \(r\) est régulier.
Vérifiez que dans le magma \((\Z,\times)\) les seuls éléments symétrisables sont \(1\) et \(-1.\)
On a trivialement \(1\times 1=1\) et \(-1\times-1=1\), dont \(1\) et \(-1\) sont symétrisables et ce sont leur propres symétriques (à gauche et à droite puisque la multiplication est commutative. L'équation \(xy=1\) d'inconnues \(x\) et \(y\) n'admet aucune autre solution que \((1,1)\) et \((-1,-1)\).
Monoïde
On rencontre très fréquemment la structure suivante en informatique et en mathématiques :
Tout magma \((X,\diamond)\) associatif et unifère est appelé
monoïde.
D'autres combinaisons des propriétés que nous avons présentées sont récurrentes. Un magma associatif est appelé un semi-groupe. Un monoïde dont tous les éléments sont symétrisables est appelé un groupe et nous y reviendrons longuement plus loin tant cette structure est importante.
Tout élément symétrisable à gauche (resp. à droite) est régulier à gauche (resp. à droite).
Un élément symétrisable admet un unique symétrique à gauche et à droite et ils sont égaux.
Soit \(x_1\) et \(x_2\) deux éléments de symétriques \(x_1'\) et \(x_2'\). Alors \(x_1\diamond x_2\) admet pour symétrique
\begin{equation}
(x_1\diamond x_2)'= x_2'\diamond x_1'.
\end{equation}
On note \(e\) l'élément neutre du monoïde \((X,\diamond)\).
1. Soit \((s,t)\in X^2\) tels que \(x\diamond s=x\diamond t\) et \(x'\) un symétrique à gauche de \(x\), alors
\begin{align*}
x'\diamond(x\diamond s)&=x'\diamond (x\diamond t)\\
(x'\diamond x)\diamond s&=(x'\diamond x)\diamond t&\ &\text{car \(\diamond\) est associative}\\
e\diamond s&=e\diamond t&\ &\text{car \(x'\) symétrique à gauche de \(x\)}.\\
s&=t&\ &\text{car \(e\) est l'élément neutre pour \(\diamond\)}.\\
\end{align*}
donc \(x\) est bien régulier à gauche. Un argumentaire symétrique permet de prouver la régularité à droite.
2. Notons \(x'\) un symétrique à gauche et \(x''\) un symétrique à droite de \(x\). Par définition, on a
\begin{equation}
\label{eq:proofpropsym}
{\color{#FF8}(x'\diamond x)} =
{\color{#88F}(x\diamond x'')} = e.
\end{equation}
Donc
\begin{align*}
{\color{#FF8}(x'\diamond x)}&=e\\
{\color{#FF8}(x'\diamond x)}\diamond x''&=e\diamond x''\quad\text{on compose à droite par \(x''\)}\\
x'\diamond{\color{#88F}(x\diamond x'')}&=x''\quad\text{associativité et \(e\) est neutre}\\
x'\diamond e&= x''\quad \text{d'après \((\ref{eq:proofpropsym})\)}\\
x'&= x''\quad\text{car \(e\) est neutre}
\end{align*}
3. Soit \(x_1\) et \(x_2\) deux éléments de \(X\) de symétriques respectifs \(x_1'\) et \(x_2'\), uniques d'après 2. Alors
\begin{align*}
(x_1\diamond x_2)\diamond(x_2'\diamond x_1')
&=(x_1\diamond (x_2 \diamond x_2'))\diamond x_1'&\ &\text{associativité}\\
&=(x_1\diamond e)\diamond x_1'&\ &\text{\(x_2'\) symétrique de \(x_2\)}\\
&=x_1 \diamond x_1'&\ &\text{\(e\) est neutre}\\
&=e&\ &\text{\(x_1'\) symétrique de \(x_1\)}
\end{align*}
On procède de la même manière pour montrer que
\[
(x_2'\diamond x_1')\diamond(x_1\diamond x_2)=e.
\]
Ce qui prouve que \(x_1\diamond x_2\) admet \(x_2'\diamond x_1'\) pour symétrique.
Ces propriétés justifient que l'on emploie le singulier défini dans le symétrique d'un élément symétrisable.
(1) Le seul entier naturel symétrisable dans \((\N,+)\) est \(0\) et il est son propre symétrique.
(2) Le seul entier naturel symétrisable dans \((\N,\times)\) est \(1\) et il est son propre symétrique.
(3) Tout élément \(x\in\Z\) est symétrisable pour l'addition par construction, sont symétrique est \(-x\).
(4) Seuls \(1\) et \(-1\) admettent un symétrique dans \((\Z,\times)\), ils sont leurs propres symétriques.
(5) Soit \(X\) un ensemble, et \((X^X,\circ)\) le magma constitué par l'ensemble des applications de \(X\) dans \(X\) munit de la loi de composition des applications. Les éléments symétrisables à gauche (resp. à droite) sont les injections (resp. surjections). Les éléments symétrisables de \((X^X,\circ)\) sont donc les bijections.
Nous avons vu que le symétrique d'un élément symétrisable \(x\) est généralement noté \(x^{-1}.\) Quand le symbole utilisé pour la loi de composition est celui de l'addition, on note plutôt \(-x\) ce symétrique.
Montrez que dans un monoïde \((X,\diamond)\), si un élément est symétrisable à gauche et à droite, ses symétriques à gauche et à droite sont nécessairement égaux.
Si \(g\) est le symétrique à gauche d'un élément symétrisable \(x\) et \(d\) son symétrique à droite, alors
\begin{align*}
g &= g * e\\
&= g * ( x * d )\\
&= (g * x) * d\\
&= e * d \\
&= d
\end{align*}
C'est donc l'associativité de la loi de composition qui l'impose.
On rappelle que la loi \(\circ\) de composition des applications d'un ensemble \(X\) dans un ensemble \(Y\) est associative et que l'application identique \(\Id\) est l'élément neutre pour cette loi. Montrez que dans le monoïde \((\N^\N,\circ)\) l'application \(f:n\mapsto n+1\) admet un symétrique à gauche mais pas à droite.
Il est évident que \( f \) est injective, elle n'est en revanche pas surjective puisque \(0\) n'a pas d'antécédent. Définissons l'application \( g: {\N} \to {\N} \) par
\[
g(n) :=\begin{cases}
0 &\text{si}\ n=0,\\
n-1 &\text{si}\ n \geqslant 1.
\end{cases}
\]
On a \(g \circ f = \Id,\) en effet :
\[
\forall n\in\N\quad (g \circ f)(n) = g(f(n)) = g(n+1) = n.
\]
Ainsi \( g \) est un symétrique à gauche de \( f \).
Supposons que \(f\) admette un symétrique à droite \(h: {\N} \to {\N} \), i.e. tel que \(f \circ h = \Id.\) Alors, pour tout \( n \in {\N} \), il existe \( m = h(n) \) tel que \(f(m) = n.\) Donc \( f \) est surjective, ce qui contredit le fait que \( 0 \notin \mathrm{Im}(f) \).
Solutions d'une équation
Résoudre une équation consiste dans la mesure du possible à isoler l'inconnue. Entre autres techniques, on peut utiliser les propriétés des lois de composition qui apparaissent immanquablement dans les équations. On tente de se débarrasser de certains opérandes, comme par exemple dans l'équation
\begin{equation}
\label{eq:equation}
{\color{orange}3}\;\underset{\up}{\color{green}\times}\; x\,=\,{\color{orange}2}\;\underset{\up}{\color{green}+}\;x
\end{equation}
d'inconnue \(x\) dans \(\Z\) qui est ici équipé de deux lois de composition : \(\times\) et \(+\). Pour ce faire, il faut a minima que les termes gênants soient réguliers. S'ils sont symétrisables, les manipulations algébriques sont plus simples.
Soit \((X,\diamond)\) un monoïde et \(a\) et \(b\) deux éléments de \(X\). Considérons l'équation
Si \(a\) admet un symétrique à gauche \(a'\), alors il existe une unique solution. En effet en composant \(a'\) aux membres gauches et droits de l'identité \((\ref{eq:eqmonoide})\), on a :
Si \(a\) admet un symétrique à droite \(a''\), alors \(x={\color{#FC0}a''\diamond b}\) est une solution, en effet
\begin{align*}
a\diamond({\color{#FF8}a''\diamond b})&=(a\diamond a'')\diamond b\quad\text{par associativité},\\
&=e\diamond b\quad\text{par symétrique à droite},\\
&=b\quad\text{car \(e\) est l'élément neutre}.
\end{align*}
D'après la proposition précédente, on sait que si \(a\) est symétrisable, \(a'=a''\) et dans ce cas \(a'\diamond b\) est l'unique solution de l'équation \((\ref{eq:eqmonoide}).\) L'étude est symétrique pour l'équation \(x\diamond a=b\) pour laquelle \(b\diamond a'\) est l'unique solution.
Comme nous venons de l'illustrer, les propriétés des lois de composition jouent un rôle essentiel dans la résolution des équations.
Résolvez l'équation \((\ref{eq:equation})\) d'inconnue \(x\) dans \(\Z\) en détaillant les propriétés des lois de compositions utilisées pour isoler \(x\).
Dans la séquence d'égalités qui va suivre, chaque égalité est équivalente à la précédente :
\begin{align*}
3\times x&=2+x\\
(3\times x)+(-x)&=(2+x)+(-x)\quad\text{on ajoute l'opposé de \(x\)}\\
(3\times x)+((-1)\times x)&=2+(x+(-x))\quad\text{associativité de \(+\)}\\
(3+(-1))\times x&=2+0\quad\text{factorisation à droite par \(x\) et symétriques pour \(+\)}\\
2\times x&=2\quad\text{neutre pour \(+\)}\\
2^{-1}\times(2\times x)&=2^{-1}\times 2\quad\text{produit à gauche par l'inverse de \(2\)}\\
(2^{-1}\times 2)\times x&=1\quad\text{associativité et symétriques pour \(\times\)}\\
1\times x&=1\quad\text{symétriques pour \(\times\)}\\
x&=1\quad\text{neutre pour \(\times\)}\\
\end{align*}
C'est évidemment très fastidieux pour un être humain et nous préférons utiliser des raccourcis. Mais pour pouvoir automatiser la résolution d'une équation, il faut maîtriser tous les rouages des lois de compositions.
Les structures algébriques abstraites et les manipulations formelles que nous venons d'étudier peuvent sembler éloignées des préoccupations pratiques des informaticiens, elles sont en réalité omniprésentes dans de nombreux domaines de l’informatique, notamment dans le traitement des langages formels et des automates, dont les expressions régulières sont une illustration bien concrète :
grep -E '^(0|1)*0[0|1]{2}$' fichier.txt
Cette commande unix cherche toutes les lignes du fichier fichier.txt qui ne sont composées que des symboles binaires \(0\) et \(1\) et qui se terminent par une séquence de trois bits dont le premier est un \(0\). Lorsque vous tapez cette commande grep, vous naviguez dans un monoïde, vous appliquez des lois de composition internes associatives, et vous bénéficiez d’algorithmes linéaires qui existent parce que ces structures sont bien définies.
Maintenant que les propriétés remarquables des magmas ont été étudiées, vous pouvez tester les propriétés de vos propres magmas finis \((X,\diamond)\) de cardinal \(2\leqslant |X|\leqslant 6\) à travers leur table de Cayley. Cette table contient les valeurs des \(|X|^2\) compositions \(x\diamond y\) à modifier, l'opérande gauche \(x\) étant placé sur la colonne à gauche et l'opérande droit \(y\) sur la première ligne de cette table :
Cardinal du magma (X, ⋄) :
Propriétés du magma \((X,\diamond)\) :
—
Pour chacun des cardinaux \(|X|\in\{1,2,3,5\},\) un seul des \(|X|^{|X|^2}\) magmas \((X,\diamond)\) possibles est un groupe et il est commutatif. Pour \(|X|=4,\) deux sont des groupes et ils sont encore commutatifs. En revanche pour \(|X|=6,\) deux magmas sont des groupes, l'un est commutatif, l'autre non : c'est le groupe symétrique \(S_3\) de degré \(3.\)
Soit \(X\) un ensemble de cardinal \(n\in\N\setminus\{0\}\). Combien existe-t-il de magmas \((X,\diamond)\) ?
Pour un ensemble donné \(X\) de cardinal \(n\), un magma \((X,\diamond)\) est caractérisé par l'application \((x,y)\mapsto x\diamond y,\) il suffitdonc de dénombrer le nombre d'applications de \(X\times X\to X.\) Par conséquent, il y en a \(n^{(n^2)}.\)
NB. Il est évident que si l'on permute les éléments de l'ensemble \(X\) d'un magma \((X,\diamond),\) on ne change pas sa nature, ce qui relativise l'explosion combinatoire \(n\mapsto n^{(n^2)}\) puisqu'il y a \(n!\) permutations possibles. Il est tentant de penser qu'il suffit de diviser le nombrede magmas \(n^{(n^2)}\) par la taille \(n!\) du groupe des permutations pour les dénombrer, mais d'une part \(n!\) ne divise pas nécessairement \(n^{(n^2)}\) et d'autre part quand on fait agir \(S_n\) sur \(X,\) les \(n!\) permutations ne transforment pas un magma en autant de magmas distincts. Par exemple pour le magma constant \(\forall (x,y)\in X²\ (x,y)\mapsto a\) où \(a\) est un élément particulier de \(X,\) toute permutation de \(S_n\) qui laisse \(a\) fixe ne change pas le magma, ce sont les \((n-1)!\) permutations qui ne permutent que les \(n-1\) autres éléments de \(X.\) Autrement dit en faisant agir les \(n!\) permutations sur \(X,\) on ne regroupe que \(n\) magmas et pas \(n!\). La résolution de ce problème de dénombrement est un problème extrêmement difficile, on ne connaît que des résultats partiels.
Lois de composition externes
Soit \(\Omega\) un ensemble. On appelle loi de composition externe sur un ensemble \(X\) à domaine d'opérateurs \(\Omega\) toute application \(\star\) de \(\Omega\times X\) dans \(X\).
De la même manière que pour une loi de composition interne, on dit qu'une partie \(A\) d'un ensemble \(X\) muni d'une loi de composition externe \(\star\) est stable pour cette loi si et seulement si
\begin{equation}
\forall(\alpha,x)\in\Omega\times A\quad \alpha\star x\in A.
\end{equation}
Dans ce cas, en restreignant la loi aux éléments de \(A\), il s'agit encore d'une loi externe, appelée loi induite par \(\star\) sur \(A\).
Si l'on dispose d'un monoïde \((X,\diamond)\) d'élément neutre \(e\), on peut par exemple construire une loi de composition externe \(\cdot\) sur \(X\) à domaine d'opérateur \(\N\) en itérant la loi interne : c'est l'application puissance \(\N\times X\rightarrow X\) définie par
\begin{equation}
(n,x)\mapsto
n\cdot x:=\begin{cases}
e&\text{si}\ n=0,\\
\overbrace{x\diamond x\diamond\cdots\diamond x}^{n\ \text{fois}\ x}&\text{si}\ n > 0.
\end{cases}
\end{equation}
Quand la loi interne \(\diamond\) est notée comme une loi multiplicative, on utilise souvent l'écriture exponentielle \(x^n\) plutôt que \(n\cdot x\) pour désigner l'élément \(x\diamond x\diamond\cdots\diamond x\) et on en déduit immédiatement que
\begin{equation}
\label{eq:additivitéexp}
x^n\diamond x^m=x^{n+m}.
\end{equation}
Nous étudierons d'autres lois de composition externes dans les prochains chapitres.
Si deux ensembles \(X\) et \(Y\) sont chacun munis d'une structure de même nature (relation binaire ou loi de composition), il est naturel de s'intéresser aux applications \(f:X\rightarrow Y\) qui ne perturbent pas les structures respectives sur ces deux ensembles. S'il s'agit de relations binaires, les images de deux éléments en relation dans \(X\) doivent rester en relation dans \(Y\) et s'il s'agit de lois de compositions, l'image du composé de deux éléments dans \(X\) doit être le composé de leurs images dans \(Y\) :
Soit \(f:X\rightarrow Y\) une application. Si \(X\) et \(Y\) sont munis respectivement des relations binaires \(\Rel{R}{X}\) et \(\Rel{R}{Y}\), on dit que \(f\) est un morphisme ou homomorphisme si et seulement si
\begin{equation}
x\,{\Rel{R}{X}}\,x'\Rightarrow f(x)\,{\Rel{R}{Y}}\,f(x').
\end{equation}
Si \((X,\diamond)\) et \((Y,\star)\) sont deux magmas, on dit que \(f\) est un morphisme si et seulement si
\begin{equation}
f(x\diamond x')=f(x)\star f(x').
\end{equation}
(1) Une application croissante est un morphisme d'ensembles ordonnés.
(2)
La notation exponentielle introduite en \((\ref{eq:additivitéexp}\)) définit un morphisme
\begin{align*}
p_x:(\N,+)&\longrightarrow(X,\diamond)\\
n&\longmapsto x^n
\end{align*}
puisque \(p_x(n+m)=x^{n+m}=x^n\diamond x^m=p_x(n)\diamond p_x(m)\).
(3)
La fonction exponentielle étudiée dans le cours d'analyse est également un morphisme de \((\R,+)\) dans \((\R,\times)\), en effet \(\text{exp}(x+y)=\text{exp}(x)\cdot\text{exp}(y)\).
(4)
La fonction définie par \(\theta\mapsto e^{i\theta}\) est un morphisme de \((\R,+)\) dans le cercle unité \(({\mathbb U},\cdot)\) muni de la multiplication complexe : \(e^{i(\theta+\theta')}=e^{i\theta}\cdot e^{i\theta'}\).
Vocabulaire
Si \(f:X\rightarrow Y\) est un morphisme injectif, on dit que c'est monomorphisme, s'il est surjectif on dit que c'est un épimorphisme.
Si \(Y=X\), on dit que \(f\) est un endomorphisme. Si \(f\) est bijective et que la bijection réciproque \(f^{-1}\) est encore un morphisme on dit que \(f\) est un isomorphisme. Un isomorphisme de \(X\) dans lui-même est appelé un automorphisme. On précise souvent la nature du morphisme, c'est-à-dire la structure qui équipe les ensembles reliés par le morphisme, on parle donc de morphisme d'ensembles ordonnés, ou de morphisme de semi-groupes ou de morphismes de groupes, etc.
Il faut retenir que si deux ensembles structurés sont isomorphes, ils sont en quelque sorte jumeaux, on peut étudier les propriétés structurelles de l'un ou l'autre indifféremment. Établir un isomorphisme entre deux ensembles structurés dont la gémellité ne saute pas aux yeux, permet de partager immédiatement toutes les propriétés structurelles que l'on a pu établir pour l'un ou l'autre.
Démontrez que si \(X\) et \(Y\) sont deux magmas, alors la bijection réciproque \(f^{-1}\) d'un morphisme bijectif \(f:X\rightarrow Y\) est nécessairement un morphisme. Démontrez que si \(X\) et \(Y\) sont munis de deux relations binaires, alors la bijection réciproque \(f^{-1}\) d'un morphisme bijectif \(f:X\rightarrow Y\) n'est pas nécessairement un morphisme. Indication : choisir une application croissante.
Notons \((X,\star)\) et \((Y,\diamond)\) ces deux magmas. Il faut donc montrer que
\[
\forall(y_1,y_2)\in Y\times Y\quad f^{-1}(y_1)\star f^{-1}(y_2)= f^{-1}(y_1\diamond y_2).
\]
Soit \(y_1\) et \(y_2\) deux éléments de \(Y\), on note \(x_1:=f^{-1}(y_1)\) et \(x_2:=f^{-1}(y_2)\). Comme \(f\) est bijective, on a \(f^{-1}\circ f={\Id}_X\) (cf. ce théorème) et on en déduit que
\begin{align*}
x_1\star x_2
&=(f^{-1}\circ f)\,\big(x_1\star x_2\big)\\
&=f^{-1}\big(f(x_1\star x_2)\big)\\
&=f^{-1}\big(f(x_1)\diamond f(x_2)\big)\quad\text{car \(f\) est un morphisme}\\
&=f^{-1}\big(y_1\diamond y_2\big)
\end{align*}
La bijection réciproque \(f^{-1}\) est donc bien un morphisme.
On considère l'ensemble ordonné \((X,=)\) (l'égalité est une relation d'ordre sur tout ensemble \(X\)) et l'ensemble ordonné \((Y,\leq)\) pour une relation d'ordre \(\leq\) quelconque définie sur \(Y\). Si \(f:X\rightarrow Y\) est une application bijective et croissante, on a donc \(x=x'\Rightarrow f(x)\leq f(x')\) mais sa bijection réciproque n'est pas nécessairement croissante, i.e. on n'a pas nécessairement \(f^{-1}(y)\leq f^{-1}(y')\Rightarrow y=y'.\) En effet, considérons l'application \(f:\Z\to\Z\) définie par \(f(x)= x+1\) qui est bijective et dont la bijectio réciproque est définie par \(f^{-1}(y)=y-1.\) Si l'on munit \(\Z\) de l'ordre naturel, \(y-1\leq y'-1\) nous permet d'affirmer que \(y\leq y'\) mais pas que \(y=y'.\)
Soit \(X\), \(Y\) et \(Z\) trois ensembles structurés et \(f:X\rightarrow Y\) et \(g:Y\rightarrow Z\) deux morphismes. Démontrez que l'application \(g\circ f\) est un morphisme de \(X\rightarrow Z\). Démontrez que si de plus les structures sont des lois de compositions et que \(f\) et \(g\) sont des isomorphismes, alors \(g\circ f\) est un isomorphisme.
Montrons le pour des relations binaires \(\Rel{R}{X}\), \(\Rel{R}{Y}\) et \(\Rel{R}{Z}\) sur ces ensembles respectivement. On a par hypothèse
\begin{align}
\label{exo:eq1}
\forall (x_1,x_2)\in X^2\quad x_1\Rel{R}{X} x_2 &\then f(x_1)\Rel{R}{Y} f(x_2)\\
\label{exo:eq2}
\forall (y_1,y_2)\in Y^2\quad y_1\Rel{R}{Y} y_2 &\then g(y_1)\Rel{R}{Z} g(y_2)
\end{align}
Soit \((x_1,x_2)\in X^2\) tel que \(x_1\Rel{R}{X} x_2\). D'après \((\ref{exo:eq1})\) on a \(f(x_1)\,\Rel{R}{Y} f(x_2)\) et on peut appliquer \((\ref{exo:eq2})\) au couple \((f(x_1),f(x_2))\) pour obtenir
\begin{align*}
\forall (x_1,x_2)\in X^2\quad x_1\,\Rel{R}{X} x_2 &\then g(f(x_1))\,\Rel{R}{Z} g(f(x_2))\\
&\then (g\circ f)(x_1)\,\Rel{R}{Z} (g\circ f)(x_2)\\
\end{align*}
Montrons le à présent pour des lois de composition internes \(+\), \(\times\) et \(\diamond\) respectivement. On a par hypothèse
\begin{align}
\label{exo:eq11}
\forall (x_1,x_2)\in X^2\quad f(x_1+x_2) &= f(x_1)\times f(x_2)\\
\label{exo:eq22}
\forall (y_1,y_2)\in Y^2\quad g(y_1\times y_2) &= g(y_1)\diamond g(y_2)
\end{align}
Et pour tout couple \((x_1,x_2)\in X^2\), on a
\begin{align*}
(g\circ f)(x_1 + x_2)
&= g(f(x_1 + x_2))&&\\
&= g(f(x_1)\times f(x_2))&\ &\text{d'après \((\ref{exo:eq11})\)}\\
&=g(f(x_1))\diamond g(f(x_2))&\ &\text{on applique \((\ref{exo:eq22})\) à \(f(x_1)\times f(x_2)\)}\\
&=(g\circ f)(x_1)\diamond(g\circ f)(x_2).&&
\end{align*}
Supposons à présent que \(f\) et \(g\) soient des isomorphismes. Si \(f\) et \(g\) sont des bijections, nous savons que \(g\circ f\) est une bijection et nous savons d'une part que \((g\circ f)^{-1} = f^{-1}\circ g^{-1}\) d'après cet exercice) et que \(f^{-1}\circ g^{-1}\) est un morphisme d'après l'exercice précédent, c'est donc bien un isomorphisme.
Transport d'une structure.
Soit \(X\) un ensemble muni d'une structure et \(Y\) un ensemble quelconque. Quand on dispose d'une bijection \(f:X\rightarrow Y\), on transporte facilement la structure de \(X\) à \(Y.\) Par exemple si \(\Rel{R}{X}\) est une relation binaire définie sur \(X\), il suffit de définir la relation \(\Rel{R}{Y}\) sur \(Y\) par
\[
y\;\Rel{R}{Y}\;y'\Leftrightarrow f^{-1}(y)\;\Rel{R}{X}\;f^{-1}(y').
\]
En vous inspirant du transport d'une structure d'ensemble ordonné ci-dessus, explicitez comment transporter une loi de composition interne et une loi de composition externe.
Soit \(f\) un morphisme surjectif d'un magma \((X,\diamond)\) dans un magma \((Y,\star)\). Démontrez que
Si \(\diamond\) est associative alors \(\star\) l'est aussi.
Si \(\diamond\) est commutative alors \(\star\) l'est aussi.
Si \(\diamond\) admet un élément neutre \(e\) alors \(\star\) aussi et \(f(e)\) est son élément.
Si \(x'\) est le symétrique de \(x\) dans \(X\), alors \(f(x')\) est le symétrique de \(f(x)\) dans \(Y\).
Compatibilité
Si plusieurs structures équipent un même ensemble, il est naturel de s'intéresser à leur cohabitation. L'omniprésence des relations d'équivalence et des lois de composition sur les ensembles justifie que l'on se questionne sur l'articulation d'une relation d'équivalence avec une loi de composition interne \(\diamond\) d'un magma \((X,\diamond)\).
Si l'on dispose d'une relation d'équivalence \(\rel\) et d'une loi de composition interne \(\diamond\) sur un ensemble \(X,\) on souhaite pouvoir équiper l'ensemble quotient \(X/\rel\) d'une loi de composition \(\overline{\diamond}\) héritée de \(\diamond\). Plus précisément, si \(A\) et \(B\) désignent deux classes d'équivalence pour \(\rel\), on veut définir la composition \(A\overline{\diamond} B\) comme la classe d'équivalence de \(a\diamond b\) si \(a\) et \(b\) désignent des représentants quelconques de \(A\) et de \(B\) respectivement. Ceci n'est possible bien sûr que si \(\overline{a\diamond b}\) ne dépend pas du choix des représentants \(a\) et \(b\), ce qui va imposer certaines conditions sur la relation \(\rel\). C'est l'objectif qu'il faut garder à l'esprit pour ne pas se perdre dans les méandres des constructions algébriques qui vont suivre.
Soit \((X,\diamond)\) un magma muni d'une relation d'équivalence \(\rel\). On dit que \(\rel\) est compatible à gauche (resp. à droite) avec la loi \(\diamond\) si et seulement si
\begin{align}
\forall(x,y,z)\in X^3\quad (x{\rel}y)&\Rightarrow ({\color{#FF8}z}\diamond x) \rel({\color{#FF8}z}\diamond y).\\
\text{resp.}\ \ \forall(x,y,z)\in X^3\quad (x{\rel}y)&\Rightarrow (x\diamond {\color{#88F}z}){\rel}(y\diamond {\color{#88F}z}).\\
\end{align}
On dit que \(\rel\) est compatible avec \(\diamond\) si elle l'est à la fois à gauche et à droite.
Trivialement, si la loi \(\diamond\) est commutative, la compatibilité à gauche est équivalente à la compatibilité à droite.
Montrez que si \((X,\diamond)\) est un magma et que \(\rel\) est une relation d'équivalence compatible à gauche et à droite avec \(\diamond\) alors
\begin{equation}
\forall(x,y,x',y')\in X^4\quad (x{\rel}y)\wedge(x'{\rel}y')\ \Rightarrow (x\diamond x'){\rel}(y\diamond y').
\end{equation}
Soit \((x,y,x',y')\in G^4\) et supposons que \((x{\rel} y)\wedge(x'{\rel} y')\). Par compatibilité à gauche on en déduit que \(({\color{#FF8}x}\diamond x'){\rel}({\color{#FF8}x}\diamond y')\) et à droite que \((x\diamond{\color{blue}y'}){\rel}(y\diamond{\color{blue}y'})\). On conclut grâce à la transitivité de \({\rel}\).
Supposons que \({\rel}\) soit compatible avec \(\diamond\) et soit \((\overline{a},\overline{b})\in (X/{\rel})^2\). Montrons que si \(a_1\) et \(a_2\) (resp. \(b_1\) et \(b_2\)) sont deux représentants quelconques de la classe \(\overline{a}\) (resp. de la classe \(\overline{b}\)), alors \(\overline{a_1\diamond b_1}=\overline{a_2\diamond b_2}.\) On a d'une part
\begin{align*}
a_1&{\rel}a_2,\\
b_1&{\rel}b_2.
\end{align*}
et la compatibilité à droite et à gauche de \(\rel\) sur \(\diamond\) permet d'en déduire que
\begin{align*}
(a_1\diamond{\color{blue}b_1})&{\rel}(a_2\diamond{\color{blue}b_1})\\
({\color{#FF8}a_2}\diamond b_1)&{\rel}({\color{#FF8}a_2}\diamond b_2).
\end{align*}
La transitivité de \(\rel\) nous donne \((a_1\diamond{\color{blue}b_1}){\rel}({\color{#FF8}a_2}\diamond b_2)\) soit \(\overline{a_1\diamond b_1}=\overline{a_2\diamond b_2}\) d'après cet exercice. La loi de composition \(*\) sur le quotient peut donc être définie par \begin{equation}
\label{eq:loiquotient}
\overline{a}\,*\,\overline{b}:=\overline{a\diamond b}.
\end{equation} puisqu'elle ne dépend pas du choix des représentants \(a\) et \(b\) des classes \(\overline{a}\) et \(\overline{b}\).
Grâce à la compatibilité de \({\rel}\) avec \(\diamond\), le quotient \(X/{\rel}\) peut donc hériter de la même loi que celle qui équipe \(X\) :
Soit \((X,\diamond)\) un magma muni d'une
relation d'équivalence \({\rel}\) compatible avec \(\diamond\) et \(\varphi: X\rightarrow X/{\rel}\) la surjection canonique. Alors il existe une unique loi de composition interne sur l'ensemble quotient \(X/{\rel}\) telle que \(\varphi\) soit un morphisme. Elle est appelée loi quotient de \(\diamond\) par \({\rel}\).
Si cette loi quotient \(*\) existe et que la surjection canonique \(\varphi\) est un morphisme, alors elle doit vérifier la proposition
\begin{equation}
\label{eq:morph}
\forall(a,b)\in X^2\quad
\varphi(a\diamond b) = \varphi(a)*\varphi(b).
\end{equation}
Mais \(X/{\rel}\) est une partition de \(X\), la proposition (\ref{eq:morph}) entraîne donc que
\begin{equation*}
\forall (\overline{a},\overline{b})\in (X/{\rel})^2\ \forall (a_1,b_1)\in A\times B\quad
\overline{a}*\overline{b} = \varphi(a_1\diamond b_1).
\end{equation*}
La loi \(*\) est donc la loi \(\overline{\diamond}\) définie en \((\ref{eq:loiquotient})\).
Par abus de langage, la loi quotient sur l'ensemble quotient est généralement notée comme la loi qui équipe l'ensemble sous-jacent.
On numérote les jours à l'aide des entiers relatifs, le jour \(0\) étant fixé (arbitrairement) au dimanche 4 mars 1962. On définit une relation binaire \({\rel}\) sur \(\Z\) par
\begin{equation}
\label{eqmod7}
x{\rel}y\iff 7\mid (y-x).
\end{equation}
Soit \(\varphi\) la surjection canonique de \(\Z\) dans \(\Z/{\rel}\). On note \(\text{dim}:=\varphi(0)\), \(\text{lun}:=\varphi(1)\),…, \(\text{sam}:=\varphi(6).\)
Démontrez que \({\rel}\) est compatible avec l'addition de \(\Z\).
Dressez la table d'addition de \(\Z/{\rel}\) pour la loi induite \(+\).
1. La relation \({\rel}\) est réflexive puisque \(7\mid 0\). Soit \((x,y)\in\Z^2\), si \(7\mid (y-x)\) alors \(7\mid (x-y)\), la relation \({\rel}\) est donc symétrique. Soit \((x,y,z)\in\Z^3\), si \(7\mid (y-x)\) et \(7\mid (z-y)\) on en déduit l'existence de deux entiers \(a\) et \(b\) tels que \(7a=y-x\) et \(7b=z-y\) puis l'égalité
\begin{align*}
7b+7a&=(z-y)+(y-x)\\
7(b+a)&=z+((-y)+y)-x\quad\text{car l'addition est associative dans}\ \Z\\
7(b+a)&=z-x.
\end{align*}
Autrement dit que \(7\mid(z-x)\), ce qui prouve que \(x\,{\rel}\,z\).
2. Les éléments de la classe de \(0\) sont les entiers relatifs \(x\) tels que \(x\,{\rel}\,0\), c'est-à-dire ceux qui sont divisibles par \(7\) ou pour paraphraser les multiples de \(7\) :
\[\overline{0}=\{7z\mid z\in\Z\}.\]
On a plus généralement pour \(k\in\ab{0}{6}\)
\[\overline{k}=\{7z+k\mid z\in\Z\}.\]
Ces \(7\) ensembles sont deux-à-disjoints, en effet \(7z+k=7z+l\) entraîne \(k=l\). D'autre part, en anticipant sur l'étude de la division euclidienne, il existe un unique \(z\in\Z\setminus\{0\}\) et un unique \(k\in\ab{0}{6}\) tels que \(x=7z+k\). Par conséquent, les ensembles \(\overline{0},\overline{1},\ldots,\overline{6}\) sont toutes les classes d'équivalence de \(\Z\) pour la relation \({\rel}\).
3. Il faut donc prouver que
\begin{equation*}
\forall(x,x',y,y')\in X^4\quad (x{{\rel}}x')\wedge(y{{\rel}}y')\ \Rightarrow (x\diamond y){{\rel}}(x'\diamond y').
\end{equation*}
Ce qui se traduit ici par
\begin{equation*}
\forall(x,x',y,y')\in X^4\quad (7\mid (x'-x))\wedge(7\mid (y'-y))\ \Rightarrow 7\mid\big((x'+y')-(x+y)\big).
\end{equation*}
Si \(7\mid (x'-x)\) et \(7\mid (y'-y)\), il existe \((k,l)\in\N^2\) tel que
\begin{align*}
7k&=x'-x\\
7l&=y'-y
\end{align*}
Et en sommant :
\begin{equation*}
7(k+l)=x'+y'-(x+y).
\end{equation*}
Ce qui permet de conclure que la relation \({\rel}\) est compatible avec l'addition dans \(\Z\). L'ensemble quotient \(\Z/{\rel}\) peut donc être muni de la loi quotient additive héritée de celle de \(\Z\).
4. La table d'addition de \(\Z/{\rel}\) est la suivante :
+
dim
lun
mar
mer
jeu
ven
sam
dim
dim
lun
mar
mer
jeu
ven
sam
lun
lun
mar
mer
jeu
ven
sam
dim
mar
mar
mer
jeu
ven
sam
dim
lun
mer
mer
jeu
ven
sam
dim
lun
mar
jeu
jeu
ven
sam
dim
lun
mar
mer
ven
ven
sam
dim
lun
mar
mer
jeu
sam
sam
dim
lun
mar
mer
jeu
ven
La construction abstraite de l'ensemble \(\Z\) des entiers relatifs dans la section suivante est une occasion d'appliquer ces différents résultats et de mieux les comprendre. Cette section est à réserver en deuxième lecture.
Exemple : une construction de \({\mathbb Z}\)
La construction de l'ensemble des entiers relatifs qui va suivre est un cas particulier de symétrisation. C'est un procédé général qui a pour objectif de rajouter les éléments qui manquent à un ensemble muni d'une loi de composition afin qu'une équation du type \((\ref{eq:eqmonoide})\) admette une solution.
Considérons le monoïde \((\N,+)\). Il est commutatif par définition de l'addition dans \(\N\) car la réunion ensembliste est commutative. Soit \((n,m)\) un couple d'entiers naturels, l'équation
n'admet de solution dans \(\N\) que si \(m\geqslant n\). Le cas échéant, on a bien sûr envie d'écrire que cette solution est égale à \(m-n\), mais nous n'avons pas défini la soustraction, c'est précisément l'objet de cette construction. Si \(x\) est une solution de \((\ref{eq:symetrisation})\), alors pour tout \({\color{#FF8}k}\in\N\), \(x\) est également solution de l'équation
Ainsi, pour \(n\) et \(m\) fixés, tous les couples de la forme \((n+{\color{#FF8}k},m+{\color{#FF8}k})\) définissent des équations \((\ref{eq:symetrisation})\) qui admettent la même solution. Il est tentant de définir la relation qui lie tous ces couples par la proposition \((n,m){{\rel}}(n',m')\Leftrightarrow n-n'=m-m'\), mais il faut l'écrire sans soustraction :
Démontrez que la relation binaire définie sur l'ensemble \(\N\times\N\) par la proposition \((\ref{eq:relbin})\) est une relation d'équivalence de surcroît compatible avec l'addition \(+\) définie en \((\ref{eq:addZ})\) sur \(\N\times\N.\)
On définit \(\Z:=(\N\times\N)\,/{\rel}\) qui, d'après le théorème de la loi quotient, est muni de la loi additive quotient puisque la relation \(\rel\) est compatible avec cette addition. On montre facilement que \((0,0)\) est l'élément neutre pour cette loi et qu'elle est associative et commutative. D'autre part, tout couple \((n,m)\) admet un symétrique, il s'agit du couple \((m,n)\), en effet
On vérifie aisément que les couples \((n,0)\) avec \(n \geqslant 0\) et les couples \((0,m)\) avec \(m > 0\) représentent des classes deux-à-deux distinctes et que ces couples représentent toutes les classes. D'autre part les classes \((0,n)\) sont les classes opposées des classes \((n,0)\) pour l'addition définie ci-dessus. On montre que le sous-ensemble de \((\Z,+)\) constitué des couples \((n,0)\) est isomorphe à \((\N,+)\), cela justifie de noter \(n\) le couple \((n,0)\). Symétriquement, on note \((-n)\) le couple \((0,n)\).
Si l'on représente le produit cartésien \(\N\times\N\) dans un repère, les représentants de type \((n,0)\) décrivent l'axe des abscisses et les représentants du type \((0,m)\) décrivent l'axe des ordonnées. La figure ci-dessous permet de visualiser les classes d'équivalence de ces couples d'entiers qui représentent les entiers relatifs de l'intervalle \(\ab{-10}{10}\).
Pour achever la construction de \(\Z\), nous ne donnerons que les grandes lignes. La multiplication est définie comme suit :
\[
(n,n')\times (m,m')=(nm+n'm',nm'+mn').
\]
Elle a pour élément neutre \(1=(1,0)\), elle est associative et commutative et compatible avec la relation d'équivalence \({\rel}\). On vérifie que
\begin{align*}
(n,0)\times(m,0)&=(nm,0)\\
((n,0)\times(0,m)&=(0,nm)\\
(0,n)\times(0,m)&=(nm,0)
\end{align*}
ce qui permet de retrouver les écritures condensées usuelles puisque l'on a noté \(n\) le couple \((n,0)\) et \(-n\) le couple \((0,n)\).
Pour la relation d'ordre, on peut montrer qu'il existe une seule relation d'ordre total sur \(\Z\), c'est la relation définie par
\[x\leqslant y\Leftrightarrow y-x\in\N,\]
qui prolonge la relation d'ordre sur les entiers naturels. On démontre que toute partie non-vide et minorée de \(\Z\) admet un plus petit élément.
Notons pour conclure cette section que le procédé de construction du corps des fractions de \(\Z\), à savoir \(\Q\) est tout à fait similaire en partant cette fois de l'équation
\begin{equation}
q\times x=p.
\end{equation}
En vous inspirant de la construction de \(\Z\), trouvez la relation d'équivalence \({\rel}\) entre couples de \(\Z\times\Z\) et la loi de composition sur \(\Z\times\Z\) pour construire l'ensemble \(\Q\) comme le quotient \((\Z\times\Z)\,/{\rel}\).
Groupes
Généralités
Nous allons aborder une dernière structure dans ce chapitre. Nous aurons besoin de la structure de groupe pour étudier le problème du taquin. D'autres structures seront abordées dans le chapitre Arithmétique. Les groupes sont omniprésents en mathématiques et font l'objet d'une attention toute particulière au point qu'une théorie à part entière leur est consacrée. Cette théorie est très utile pour résoudre de nombreux problèmes de combinatoire, de géométrie, etc. Les chimistes en font grand usage dans l'étude des structures moléculaires et leurs symétries.
Un magma \((X,\diamond)\) unifère et associatif dont tous les éléments sont symétrisables est appelé un groupe. Si l'ensemble \(X\) est fini, le groupe \((X,\diamond)\) est appelé groupe fini d'ordre \(|X|\).
(1) L'ensemble des entiers relatifs \(\Z\) muni de l'addition est un groupe, de surcroît commutatif (on dit aussi groupe abélien*Niels Henrik Abel fut un mathématicien norvégien qui a démontré, entre autres, que l'on ne pouvait pas résoudre une équation de degré \(\geqslant 5\) par radicaux.). Nous reviendrons en détail sur ce groupe en arithmétique.
(2) Le sous-ensemble \(\{-1,1\}\) de \(\Z\) muni de la multiplication est un groupe commutatif.
(3) L'ensemble des nombres complexes de module \(1\) muni de la multiplication forme un groupe commutatif.
(4) L'ensemble des symétries du carré dans le plan euclidien contenant \(4\) rotations et \(4\) réflexions, est un groupe (non-commutatif).
Par analogie avec l'addition dans \(\Z\), quand la loi de groupe est notée additivement, on note souvent \(0\) l'élément neutre au lieu de \(e\) et on parle d'opposé d'un élément \(x\) plutôt que de symétrique que l'on note généralement \((-x)\). De même, quand la loi de groupe est notée multiplicativement, on note souvent \(1\) l'élément neutre au lieu de \(e\) et on parle d'inverse d'un élément \(x\) plutôt que de symétrique, que l'on note généralement \(x^{-1}\). Par abus de langage, on parle souvent du groupe \(G\) pour signifier \((G,\diamond)\), confondant ainsi le groupe avec l'ensemble sous-jacent.
Soit \((G,\diamond)\) et \((G',\star)\) deux groupes notés multiplicativement et \(f:G\rightarrow G'\) un morphisme de groupes. On vérifie que l'image de l'élément neutre \(e\) de \((X,\diamond)\) est l'élément neutre \(e'\) de \((X',\star)\), i.e.
L'ensemble des entiers relatifs \(\Z\) est un groupe commutatif pour l'addition, et \(\Z\setminus\{0\}\) n'est pas un groupe pour la multiplication. En revanche l'ensemble des réels \(\R\) est un groupe commutatif pour l'addition et \(\R\setminus\{0\}\) est un groupe commutatif pour la multiplication.
On considère une famille \((G_i,\diamond_i)_{i\in I}\) de groupes et on note \(G\) le produit de la famille \((G_i)_{i\in I}.\) On définit la loi produit \(\diamond\) sur \(G\) par
\begin{equation}
x\diamond y = (x_i\diamond_i y_i)_{i\in I}.
\end{equation}
Montrez que chaque projection \(p_i:G\rightarrow G_i\) est un morphisme surjectif de groupes. Montrez que le groupe produit \((G,\diamond)\) est commutatif si et seulement si chacun des groupes \((G_i,\diamond_i)\) est commutatif.
Application : définissez l'addition sur des \(n\)-uplets de \(\R^n\).
Sous-groupes
On appelle sous-groupe d'un groupe \((G,\diamond)\), tout groupe \((H,\diamond)\) où \(H\) est une partie stable de \(G\) munie de la loi induite par celle de \(G\). On note alors \(H \leq G\) ou \(H < G\) si de plus \(H\neq G\).
(1) Le sous-ensemble \(\{-1,1\}\) de \(\Z\) muni de la multiplication induite est un sous-groupe du groupe \((\Z,\times)\).
(2) L'ensemble \(3\Z:=\{3k\mid k\in\Z\}\) des multiples de \(3\) muni de l'addition est un sous-groupe de \((\Z,+)\).
(3) L'ensemble des nombres complexes de module un est un sous-groupe du groupe \((\C,\times)\).
Si \(H\) est un sous-groupe de \(G\), l'injection canonique \(j:H\rightarrow G\) vérifie \(j(x\diamond y)=j(x)\diamond j(y)\), c'est donc un morphisme de groupes. Et d'après \((\ref{eq:imneutre})\) et \((\ref{eq:iminverse})\), l'élément neutre de \(H\) est celui de \(G\) et le symétrique d'un élément de \(H\) est le même que son symétrique dans \(G\) ce qui prouve la proposition suivante :
Un groupe et ses sous-groupes ont le même élément neutre. Le symétrique d'un élément d'un sous-groupe est identique à celui qu'il a dans le groupe.
Le théorème suivant est particulièrement utile, il fournit plusieurs caractérisations d'un sous-groupe, soit autant de pistes pour démontrer qu'un sous-ensemble \(H\subseteq G\) muni de la loi induite par celle du groupe \((G,\diamond)\) est bien un sous-groupe de \(G\).
Soit \((G,\diamond)\) un groupe d'élément neutre \(e\) et \(H\) une partie de \(G.\) Les quatre assertions suivantes sont équivalentes :
\(H\) est un sous-groupe de \(G\) ;
\(H\) est stable, \(e\in H\) et \(\forall x\in H\ \ x^{-1}\in H\) ;
\(H\) est stable, \(H\not=\varnothing\) et \(\forall x\in H\ \ x^{-1}\in H\) ;
\(H\not=\varnothing\) et \(\forall (x,y)\in H^2\ \ x\diamond y^{-1}\in H\).
Montrons que \((1)\then(2)\). Par définition \(H\) est stable pour \(\diamond\) et la proposition précédente permet de conclure.
Montrons que \((2)\then(3)\). C'est évident puisque \(e\in H\).
Montrons que \((3)\then(4)\). C'est évident puisque \(y^{-1}\in H\) et que \(H\) est stable.
Montrons que \((4)\then(2)\). Puisque \(H\) n'est pas vide, il existe au moins un \(x\in H\), on peut donc appliquer la deuxième partie de l'hypothèse sur le couple \((x,x)\), soit \(x\diamond x^{-1}=e\in H\). On peut à présent appliquer la deuxième partie de l'hypothèse au couple \((e,x)\), soit \(e\diamond x^{-1}=x^{-1}\in H\). Pour la stabilité, \(x\diamond y=x\diamond(y^{-1})^{-1}\).
On conclut avec \((2)\then(1)\). \(H\) étant stable la loi \(\diamond\) induite sur \(H\) est associative et admet \(e\) pour élément neutre et tout \(x\in H\) admet pour symétrique \(x^{-1}\).
Si \((G,\diamond)\) est un groupe, \((G,\diamond)\) est évidemment un sous-groupe de \((G,\diamond)\), c'est le plus grand élément pour la relation \(\subseteq.\) Pour cette même relation d'ordre, le plus petit sous-groupe de \(G\) est le sous-groupe \((\{e\},\diamond)\) où \(e\) est l'élément neutre de \(G\) pour la loi \(\diamond\). On vérifie aisément que si \(H\) est un sous-groupe de \(G\) qui est lui même un sous-groupe de \(K\), alors \(H\) est un sous-groupe de \(K\).
Soit \((G,\diamond)\) un groupe. Vérifiez que l'ensemble noté \({S}(G)\) des bijections de l'ensemble \(G\) dans lui-même muni de la loi de composition des applications est un groupe. Montrez que le sous-ensemble des automorphismes muni de la loi induite \(\circ\), noté \((\text{Aut}(G),\circ)\) est un sous-groupe de \(({S}(G),\circ)\).
L'intersection d'une famille de sous-groupes d'un groupe \(G\) est un sous-groupe de \(G\). Soit \(A\subseteq G\) une partie d'un groupe \(G\), l'intersection de tous les sous-groupes de \(G\) qui contiennent \(A\) n'est jamais vide puisque \(G\) est un sous-groupe de \(G\) et contient \(A\).
Soit \(G\) un groupe et \(A\subseteq G\). On appelle sous-groupe engendré par \(A,\) le plus petit sous-groupe \(H\leq G\) qui contient \(A,\) on le note \(\langle A\rangle.\) C'est l'intersection de tous les sous-groupes de \(G\) qui contiennent \(A\). On dit que \(A\) est une partie génératrice de \(H.\) Par convention \(\langle\varnothing\rangle=\{e\}.\)
On admettra le théorème suivant :
Soit \((G,\diamond)\) un groupe noté multiplicativement d'élément neutre \(e\) et \(A\) une partie de \(G\). Si \(x^1\) désigne \(x\) et \(x^{-1}\) le symétrique de \(x\), alors le sous-ensemble \(H\) des produits quelconques d'éléments \(a\) ou \(a^{-1}\) de \(A\), i.e de la forme
\begin{equation}
a_1^{\epsilon_1}\diamond a_2^{\epsilon_2}\diamond\cdots\diamond a_n^{\epsilon_n}\quad\text{où}\ \ \epsilon_i\in\{-1,1\}.
\end{equation}
est le sous-groupe \(\langle A\rangle\) de \(G\) engendré par \(A.\)
On appelle groupe monogène tout groupe engendré par un singleton. Un groupe monogène et fini est appelé groupe cyclique.
Soit \(f:G\rightarrow G'\) un morphisme de groupes. Alors l'image directe d'un sous-groupe \(H\) de \(G\) est un sous-groupe de \(G'\) pour la loi induite et l'image réciproque d'un sous-groupe \(H'\) de \(G'\) est un sous-groupe de \(G\) pour la loi induite.
L'image du groupe \(G\) tout entier et l'image réciproque du singleton \(\{e'\}\) constitué de l'élément neutre de \(G'\) sont donc des sous-groupes de \(G'\) et \(G\) respectivement.
Soit \(f:G\rightarrow G'\) un morphisme de groupes. Alors \(f(G)\) est un sous-groupe de \(G'\) appelé image de \(G\) et noté \(\text{Im}(G)\). Si \(e'\) est l'élément neutre de \(G'\), alors \(f^{-1}(\{e'\})\) est un sous-groupe de \(G\) appelé noyau de \(f\) et noté \(\text{Ker}(f)\).
L'image et le noyau d'un morphisme fournissent des critères simples pour décider s'il est surjectif ou injectif, ce qui s'avère très utile en pratique :
Un morphisme de groupes \(f:G\rightarrow G'\) est surjectif si et seulement si \(\text{Im}(f)=G',\) et injectif si et seulement si \(\text{Ker}(f)=\{e\}\) où \(e\) désigne l'élément neutre pour la loi de \(G\).
On désignera par \(\diamond\) et \(\star\) les lois de composition internes respectives des groupes \(G\) et \(G'\) notée multiplicativement et \(e\) et \(e'\) leurs éléments neutres respectifs.
Le résultat est évident pour la surjection par définition. Pour l'autre partie, on sait que l'image de \(e\) est \(e'\), que \(f\) soit injective ou non, mais si c'est cas \(e\) est l'unique élément dont l'image est \(e'\), autrement dit \(\text{Ker}(f)=\{e\}\). Réciproquement, supposons que \(\text{Ker}(f)=\{e\}\). On veut prouver que
\[\forall (x,y)\in G\times G\ \ f(x)=f(y)\Rightarrow x=y.\]
L'élément \(f(y)\) admet un symétrique \(f(y)^{-1}\) (notation multiplicative) dans \(G'\) puisqu'il s'agit d'un groupe, donc si \(f(x)=f(y)\),
\begin{align*}
f(x)\star f(y)^{-1}&=f(y)\star f(y)^{-1}\\
f(x)\star f(y)^{-1}&=e'\\
f(x\diamond y^{-1})&=e'
\end{align*}
Autrement dit, \(x\diamond y^{-1}\in\text{Ker}(f)\), soit :
\begin{align*}
x\diamond y^{-1}&=e\\
(x\diamond y^{-1})\diamond y&=e\diamond y\\
x\diamond (y^{-1})\diamond y)&=y\\
x\diamond e&=y\\
x&=y.
\end{align*}
et \(f\) est donc injective.
Justifiez chaque égalité de la preuve ci-dessus en identifiant les propriétés des lois de groupe qui ont été appliquées.
On rappelle que le centre de \(G\) est la partie \(Z_G\) des éléments de \(G\) qui commutent avec tous les éléments du groupe, i.e.
Soit \(a\in Z_G\), on a donc \(\forall x\in G\ \ x\diamond a = a \diamond x\) et en composant à droite par le symétrique de \(a\) noté \(a^{-1},\) on a nécessairement
Démontrez que l'application \(\varphi_a:G\rightarrow G\) définie par \(x\mapsto\ a\diamond x\diamond a^{-1}\) est un automorphisme du groupe (dit automorphisme intérieur de \(G\)).
Quel est l'automorphisme réciproque de \(\varphi_a\) ?
Démontrez que l'application \(\varphi:a\mapsto \varphi_a\) est un morphisme du groupe \((G,\diamond)\) dans le groupe \((\text{Aut}(G),\circ)\).
Vérifiez que \(\text{Ker}(\varphi)=Z(G).\)
1. C'est un morphisme, en effet en notant \(e\) l'élément neutre pour \(\diamond\), on a \(a\diamond a^{-1}=e\) et on en déduit
\begin{align*}
\varphi_a(x\diamond y)
&=a\diamond x\diamond y\diamond a^{-1}\\
&=a\diamond x\diamond (a^{-1}\diamond a)\diamond y\diamond a^{-1}\\
&=(a\diamond x\diamond a^{-1})\diamond (a\diamond y\diamond a^{-1})\\
&=\varphi_a(x)\diamond\varphi_a(y).
\end{align*}
Il est injectif, en effet
\begin{equation*}
\varphi_a(x)=\varphi_a(y)\iff
a\diamond x\diamond y\diamond a^{-1} = a\diamond y\diamond y\diamond a^{-1}
\end{equation*}
Il suffit de composer les deux membres de l'égalité à gauche par \(a^{-1}\) et à droite par \(a\) pour obtenir \(x=y.\) Il est également surjectif, soit \(y\in G\), l'élément \(x:=\varphi_{a^{-1}}(y)=a^{-1}\diamond y\diamond a\) est un antécédent de \(y\) :
\begin{align*}
\varphi_a(x)&=a\diamond(a^{-1}\diamond y \diamond a)\diamond a^{-1}\\
&=(a\diamond a^{-1})\diamond y \diamond (a\diamond a^{-1})\\
&=y.
\end{align*}
Et nous savons que pour une loi de composition, un morphisme bijectif est un isomorphisme.
2. On a \(\varphi_a\circ\varphi_{a^{-1}}=\varphi_{a^{-1}}\circ\varphi_a={\Id}_G\), donc \(\varphi_a^{-1}=\varphi_{a^{-1}}\).
3. Soit \((a,b)\in G^2\). On a \(\varphi(a\diamond b)=\varphi_{a\diamond b}\), or \(\forall x\in G\),
\begin{align*}
\varphi_{a\diamond b}(x)
&= (a\diamond b)\diamond x \diamond (a\diamond b)^{-1}\\
&= (a\diamond b)\diamond x \diamond (b^{-1}\diamond a^{-1})\\
&= a\diamond(b\diamond x\diamond b^{-1})\diamond a^{-1}\\
&= \varphi_a(b\diamond x\diamond b^{-1})\\
&= \varphi_a(\varphi_b(x))\\
&= (\varphi_a\circ\varphi_b)(x)
\end{align*}
Donc \(\varphi(a\diamond b)=\varphi_a\circ\varphi_b\).
4. Par définition \(\text{Ker}(\varphi)=\{a\in G\mid \varphi_a={\Id}_G\}.\) Mais \(\varphi_a={\Id}_G\) est équivalent à
\begin{equation*}
\forall x\in G\ \varphi_a(x)=x\ \iff\ \forall x\in G\ a\diamond x\diamond a^{-1}=x \iff\ \forall x\in\
G\ a\diamond x=x\diamond a.
\end{equation*}
Ce qui prouve que \(\text{Ker}(\varphi)=Z(G)\).
Soit \(f:G\rightarrow G'\) un morphisme de groupes. Montrez que
\[\forall x\in G\quad (f(x^{-1}) = (f(x))^{-1}.\]
Autrement dit que l'image d'un symétrique est le symétrique de son image.Montrez que si \(f\) est injective, alors
\[\forall y\in \text{Im}(f)\quad (f^{-1}(y^{-1})) = x^{-1}.\]
Sous-groupes normaux
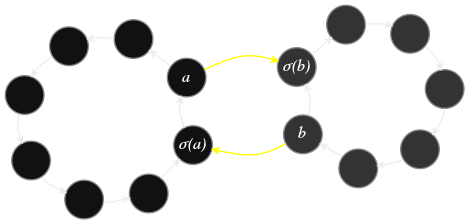
On dit que deux éléments \(x\) et \(x'\) d'un groupe \((G,\diamond)\) sont conjugués si et seulement s'il existe \({\color{lightblue}a}\in G\) tel que
\begin{equation}
\label{eq:conjugaison}
x'= {\color{lightblue}a}\diamond x\diamond {\color{lightblue}a^{-1}}.
\end{equation}
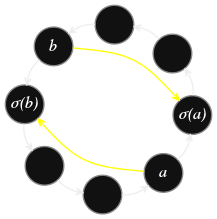
Métaphoriquement, on peut voir les éléments d’un groupe \(G\) comme des machines qui opèrent grâce à la loi de composition \(\diamond.\) Pour \(x\) et \(y\) dans \(G\), écrire \(x\diamond y\) signifie que la machine \(x\) agit sur \(y.\) Si \(a\in G\), la machine conjuguée à \(x,\)
\[
x' = {\color{orange}a\diamond x\diamond a^{-1}},
\]
réalise le même travail que \(x\) mais après une délocalisation de l’élément sur lequel elle agit. En effet, pour calculer \(x'\diamond y\) :
on transporte la matière première \(y\) : \(a^{-1}\diamond y\) ;
on fait agir la machine \(x\) : \(x\diamond(a^{-1}\diamond y)\) ;
on rapatrie le produit fini par \(a\) : \(a\diamond(x\diamond(a^{-1}\diamond y))\)
Et grâce à l'associativité de la loi de composition \(\diamond\) :
\[
a\diamond(x\diamond(a^{-1}\diamond y))
= ({\color{orange}a\diamond x\diamond a^{-1}})\diamond y
\]
La conjugaison correspond donc à faire agir la même machine, mais sur des éléments déplacés dans le groupe.
Si le groupe est commutatif, l'égalité \(x'=a\diamond x \diamond a^{-1}\\\) devient
\begin{align*}
x'&=(a\diamond x) \diamond a^{-1}\quad\text{associativité}\\
&=(x\diamond a) \diamond a^{-1}\quad\text{commutativité}\\
&=x\diamond (a \diamond a^{-1})\quad\text{associativité}\\
&=x\diamond e\quad\text{éléments symétriques}\\
&=x\quad\text{élément neutre}
\end{align*}
Autrement dit, tout élément d'un groupe commutatif n'a pour conjugué que lui-même. La notion de conjugaison n'a d'intérêt que pour des groupes qui ne sont pas commutatifs.
Vérifiez que la relation de conjugaison sur un groupe \(G\) est une relation d'équivalence. Soit \(x\in Z(G)\), montrez que la classe de conjugaison de \(x\) est réduite à \(\{x\}.\)
Elle est réflexive puisque \(x\) est conjugué avec lui même \(x = e\diamond x\diamond e\). Elle est symétrique puisque si \(x'= a\diamond x\diamond a^{-1}\) alors \(x= {\color{lightblue}a^{-1}}\diamond x'\diamond ({\color{lightblue}a^{-1}})^{-1}\). Elle est également transitive puisque si \(y={\color{#FF8}a\diamond x\diamond a^{-1}}\) et \(z= b\diamond{\color{#FF8}y}\diamond b^{-1}\), alors
\begin{align*}
z&= b\diamond ({\color{#FF8}a\diamond x\diamond a^{-1}})\diamond b^{-1}\\
&= (b\diamond a)\diamond x\diamond (a^{-1}\diamond b^{-1})\quad\text{car la loi est associative}\\
&= (b\diamond a)\diamond x\diamond (a^{-1}\diamond b^{-1})\\
&= (b\diamond a)\diamond x\diamond (b\diamond a)^{-1}\\
\end{align*}
Il suffit de constater que la classe de conjugaison d'un élément \(x\in G\) est l'ensemble
\[\overline{x}:=\{a\diamond x\diamond a^{-1}\such a\in G\}\]
et comme \(x\in Z(G)\), il commute avec tous les éléments de \(G\), donc \(a\diamond x\diamond a^{-1}=a\diamond a^{-1}\diamond x=x.\)
Soit \((G,\diamond)\) un groupe, \(H\) un sous-groupe et \(a\in G\). Montrez que \(a\diamond H\diamond a^{-1}\) est un sous-groupe de \(G.\)
On va utiliser la propriété 2 du théorème de caractérisation des sous-groupes.
Notons \(H':=a\diamond H\diamond a^{-1}\) et considérons \(x'\) et \(y'\) deux éléments de \(H'.\) Alors il existe \(x\) et \(y\) dans \(H\) tels que \(x'=a\diamond x\diamond a^{-1}\) et \(y'=a\diamond y\diamond a^{-1}.\) Donc
\begin{align*}
x'\diamond y'
&= (a\diamond x\diamond a^{-1})\diamond(a\diamond y\diamond a^{-1})\\
&= (a\diamond x)\diamond (a^{-1}\diamond a)\diamond (y\diamond a^{-1})\\
&= (a\diamond x)\diamond (y\diamond a^{-1})\\
&= a\diamond (x\diamond y)\diamond a^{-1}
\end{align*}
Par conséquent \(x'\diamond y'\in H'\). D'autre part, comme \(a\diamond e\diamond a^{-1}=a\diamond a^{-1}=e\) on a \(e\in H'\). Reste à montrer que si \(x'\in H'\), \((x')^{-1}\in H'\). On a \(x'=a\diamond x\diamond a^{-1}\), vérifions que \((x')^{-1}=a\diamond x^{-1}\diamond a^{-1}\) :
\begin{align*}
(a\diamond x\diamond a^{-1})\diamond (a\diamond x^{-1}\diamond a^{-1})
&=(a\diamond x)\diamond (a^{-1}\diamond a)\diamond (x^{-1}\diamond a^{-1})\\
&=(a\diamond x)\diamond (x^{-1}\diamond a^{-1})\\
&=a\diamond (x\diamond x^{-1})\diamond a^{-1}\\
&=a\diamond a^{-1}\\
&=e
\end{align*}
On obtient \((a\diamond x^{-1}\diamond a^{-1})\diamond (a\diamond x\diamond a^{-1})=e\) de la même manière.
Soit \(G\) un groupe, \(a\in G\) et \(H\) et \(H'\) deux sous-groupes de \(G\). On dit que \(H\) et \(H'\) sont conjugués par \(a\) si et seulement si \(H'=a\diamond H\diamond a^{-1}\).
On appelle sous-groupe normal (ou distingué) d'un groupe \((G,\diamond)\) tout sous-groupe \(H\) de \(G\) égal à tous ses conjugués :
\begin{equation}
\label{eq:ssgd}
\forall a\in G\quad H=a\diamond H\diamond a^{-1}.
\end{equation}
On note alors \(H\trianglelefteq G\) et \(H\triangleleft G\) si de plus \(H\neq G.\)
Si \((G,\diamond)\) est un groupe d'élément neutre \(e\), alors \((\{e\},\diamond)\) et \((G,\diamond)\) sont deux sous-groupes normaux de \((G,\diamond),\) dits triviaux et s'il n'y en a pas d'autres, alors \((G,\diamond)\) est appelé un groupe simple.
Les groupes simples et finis sont centraux dans l'étude générale des groupes finis, car ces derniers sont tous construits à partir de ces groupes simples. Leur très difficile classification a demandé des dizaines d'années de recherche et s'est achevée au début des années 1980.
Si un groupe \(G\) est commutatif, tous ses sous-groupes sont normaux, cette notion a donc surtout un intérêt dans l'étude des groupes non-commutatifs. On sait déjà que l'image ou l'image réciproque d'un sous-groupe par un morphisme de groupe est un sous-groupe et on peut montrer que l'image et l'image réciproque d'un sous-groupe normal par un morphisme de groupe sont des sous-groupes normaux. En corollaire, le noyau d'un morphisme de groupe est toujours un sous-groupe normal.
L'étude des sous-groupes normaux est motivée par la caractérisation des relations d'équivalence qui sont compatibles avec une loi de groupe. En effet, il faut se souvenir que l'on ne peut transporter une loi de composition qui équipe un ensemble sur son ensemble quotient, qu'à la condition que la relation d'équivalence soit compatible avec sa loi de composition. Dans le cas particulier d'un groupe, une relation d'équivalence compatible à gauche (ou à droite) avec la loi du groupe est entièrement caractérisée par un sous-groupe de \(G.\) Si l'on exige à la fois la compatibilité à gauche et à la compatibilité à droite, ce sous-groupe est nécessairement normal.
Soit \((G,\diamond)\) un groupe. Une relation d'équivalence \({\rel}\) sur \(G\) est compatible à gauche (resp. à droite) avec la loi \(\diamond\) si et seulement si elle est de la forme
\begin{equation}
\label{eq:rgrd}
x{\color{orange}{\rel}}y\ \Leftrightarrow\ x^{-1}\diamond y\in H\qquad\text{resp.}\ \ x{\color{lightblue}{\rel}}y\ \Leftrightarrow\ y\diamond x^{-1}\in H,
\end{equation}
où \(H\leq G\).
Nous ne faisons la preuve que pour la compatibilité à gauche, elle est similaire pour la compatibilité à droite. On se donne une relation d'équivalence \({\rel}\) sur \(G\) compatible à gauche, autrement dit
\[
\forall(x,y,z)\in G^3\ \ x{{\rel}}y\Rightarrow ({\color{#88F}z}\diamond x){{\rel}}({\color{#88F}z}\diamond y).
\]
On note \(H\) la classe d'équivalence de l'élément neutre \(e\) pour \({\rel}\). Soit \((x,y)\in G^2\) tels que \(x{{\rel}}y.\) Comme \({\rel}\) est compatible à gauche avec la loi \(\diamond\), on a \((x^{-1}\diamond x){{\rel}}(x^{-1}\diamond y)\), soit \(e{{\rel}}(x^{-1}\diamond y)\) et donc \(x^{-1}\diamond y\in H.\) Inversement si \(x^{-1}\diamond y\in H\) alors \((x^{-1}\diamond y){{\rel}}e\) et donc \(x\diamond(x^{-1}\diamond y){{\rel}}x\) soit \((x\diamond x^{-1})\diamond y{{\rel}}x\) par associativité et finalement \(y{{\rel}}x\) ou encore \(x{{\rel}}y\) puisque la relation est symétrique. Donc
\[
\forall(x,y)\in G\times G\quad x{{\rel}}y\Leftrightarrow x^{-1}\diamond y\in H.
\]
Montrons que \(H\) est un sous-groupe de \(G\). Soit \(x\) et \(y\) deux éléments quelconques de \(H\). Comme \(e\in H\), \(x{{\rel}}e\) et \(e{{\rel}}y\) et par transitivité de la relation, \(x{{\rel}}y\) soit \(x^{-1}\diamond y\in H\).
Réciproquement soit \(H\leq G\). La relation \({\rel}\) définie par \(x{{\rel}}y\Leftrightarrow x^{-1}\diamond y\in H\) est réflexive puisque pour tout \(x\in G\), \(x^{-1}\diamond x=e\) et \(e\in H\). Elle est symétrique car si \(x^{-1}\diamond y\in H\), son inverse \((x^{-1}\diamond y)^{-1}=y^{-1}\diamond x\) appartient à \(H\) puisque \(H\) est un sous-groupe de \(G\) et donc \(y{\rel}x\). Soit \((x,y,z)\in G^3\), si \(x{\rel}y\) et \(y{\rel}z\) soit \(x^{-1}\diamond y\in H\) et \(y^{-1}\diamond z\in H\), alors leur composé \((x^{-1}\diamond y)\diamond(y^{-1}\diamond z)=x^{-1}\diamond z\) appartient à \(H\) puisque \(H\) est un groupe, et donc \(x{\rel}z\) ce qui prouve que \({\rel}\) est transitive.
La relation est également compatible à gauche. En effet, soit \((x,y,z)\in G^3\) tel que \(x{\rel}y\), i.e. \({\color{orange}x^{-1}\diamond y}\in H\). On a
\begin{align*}
{\color{orange}(z\diamond x)^{-1}\diamond(z\diamond y)}&=(x^{-1}\diamond z^{-1})\diamond(z\diamond y)\quad\text{inverse d'un produit}\\
&=x^{-1}\diamond(z^{-1}\diamond z)\diamond y\quad\text{associativité}\\
&=x^{-1}\diamond e\diamond y\quad\text{symétrique}\\
&={\color{orange}x^{-1}\diamond y}\quad\text{neutre}.
\end{align*}
Ce qui prouve que \((z\diamond x){\rel}(z\diamond y)\).
Les classes d'équivalence des relations \(\color{orange}{\mathscr R}_g\) et \(\color{lightblue}{\mathscr R}_d\) définies en \((\ref{eq:rgrd})\) sont respectivement les ensembles
\begin{equation}
a\diamond H:=\{a\diamond h\mid h\in H\}\quad\text{et}\quad H\diamond a:=\{h\diamond a\mid h\in H\},
\end{equation}
appelés classes à gauche et classes à droite suivant \(H\).
L'application \(x\mapsto x^{-1}\) de \(G\) dans \(G\) définit une bijection entre \(a\diamond H\) et \(H\diamond a^{-1}\), autrement dit l'ensemble des inverses des éléments de \(a\diamond H\) est l'ensemble \(H\diamond a^{-1}\). Par conséquent, les deux ensembles quotients \(G/{\mathscr R}_g\) et \(G/{\mathscr R}_d\) sont équipotents et s'ils sont finis leur cardinal est appelé indice de \(H\) dans \(G\), on le note \((G:H)\) ou \([G:H]\) ou encore \(|G:H|\). Le théorème qui suit est un résultat fondamental, il est omniprésent dans les raisonnements qui concernent les groupes finis :
L'ordre d'un sous-groupe \(H\) d'un groupe fini \(G\) divise l'ordre du groupe \(G\) et \(|G|\,/\,|H|=(G:H)\).
L'application \(x\mapsto a\diamond x\) définit une bijection de \(H\) dans \(a\diamond H\), les différentes classes à gauche sont donc équipotentes et comme elles forment une partition de \(G\), le principe des bergers permet de conclure.
Soit \({\rel}\) une relation d'équivalence compatible avec la loi \(\diamond\), autrement dit compatible à gauche et à droite. Soit \(H\) la classe d'équivalence de l'élément neutre \(e\). On sait que \(H\) est un sous-groupe de \(G\) et que \(\forall x\in G\), \(x{{\rel}}y\) si et seulement si \(y\in x\diamond H\) et \(y\in H\diamond x\), soit
soit \(H\trianglelefteq G\). Réciproquement si \(H\trianglelefteq G\), la relation \({\rel}\) définie par \(x{{\rel}}y\) si et seulement si \(x^{-1}\diamond y\in H\) qui équivaut à \(y\diamond x^{-1}\in H\) est compatible avec la loi \(\diamond\). Par conséquent :
Une relation d'équivalence \({\rel}\) définie sur un groupe \((G,\diamond)\) est compatible avec la loi \(\diamond\) si et seulement s'il existe un sous-groupe normal \(H\trianglelefteq G\) tel que
\[
x{{\rel}}y\ \Leftrightarrow\ x^{-1}\diamond y\in H.
\]
Dans ce cas l'ensemble quotient \(G/{\rel}\) est un groupe appelé groupe quotient et on le note \(G/H\).
Puisque les relations d'équivalence compatibles avec une loi de groupe sont complètement caractérisées par les sous-groupes normaux du groupe, le groupe quotient est noté \(G\,/\,H\) plutôt que \(G\,/\,{\rel}\). La surjection canonique \(\varphi:G\rightarrow G\,/\,H\) est alors un morphisme de groupes.
Nous savons déjà que tout sous-groupe d'un groupe commutatif est normal. \((\Z,+)\) est un groupe commutatif, les relations d'équivalence compatibles avec l'addition sur \(\Z\) sont donc du type
\[x{{\rel}}y\Leftrightarrow y-x\in H\]
où \(H\) est un sous-groupe de \(\Z\). L'étude de ce groupe particulier est le point de départ de l'arithmétique, ce que nous aborderons au chapitre éponyme Arithmétique.
Les groupes sont souvent notés multiplicativement mais ne sont pas toujours commutatifs, et donc si \((x_i)_{i\in I}\) est une famille d'éléments d'un groupe non-commutatif, on ne peut pas définir son produit en général. Néanmoins si la loi est associative et que l'ensemble d'indexation est l'intervalle \(\ab{1}{n}\) de \(\N\), on définit les produits dans l'ordre croissant (resp. décroissant) des indices :
\begin{align*}
\prod_{i=1}^n x_i&:=x_1.x_2\,\ldots\,x_{n-1}.x_n,\\
\prod_{i=n}^1 x_i&:=x_n.x_{n-1}\,\ldots\,x_2.x_1.
\end{align*}
Le groupe symétrique
L'ensemble des permutations des éléments d'un ensemble joue un rôle très important, non seulement en mathématiques mais également en informatique. Par exemple, tous les algorithmes de tri sont intimement reliés à l'étude de cet ensemble. Nous verrons d'ailleurs que beaucoup de résultats mathématiques de cette section ne sont rien d'autres que des algorithmes déjà connus du lecteur avant même d'avoir étudié le groupe symétrique.
L'ensemble des bijections d'un ensemble \(X\) dans lui-même est noté \(S(X)\) ou \({\mathfrak S}(X)\) et ses éléments sont appelés permutations de \(X\).
Comme n'importe quelle application, on peut représenter une permutation \(\sigma:X\to X\) avec son diagramme sagittal. L'ensemble de départ et d'arrivée étant confondus, on se contente de connecter les éléments de \(X\) entre eux avec les arcs \((x,\sigma(x))\) de son graphe, sans représenter les boucles pour les points fixes.
Soit \(X=\{a,b,c,d\}\) et \(\sigma(a)=a,\) \(\sigma(b)=c,\) \(\sigma(c)=d\) et \(\sigma(d)=b\) :
Diagramme sagittal de la permutation \(\sigma\).
Le magma \((S(X),\circ)\) où \(\circ\) est la loi de composition des applications est un groupe appelé groupe symétrique de \(X\). Si \(X=\ab{1}{n}\), on l'appelle groupe symétrique de degré n et on le note \(S_{n}\) ou \({\mathfrak S}_n\).
Nous avons vu en exercice que la composée de deux bijections est une bijection, le sous-ensemble \(\Sn(X)\) de \(X^X\) constitué des bijections est donc une partie stable pour la loi de composition \(\circ\) faisant de \((\Sn(X),\circ)\) un magma. L'associativité de la loi de composition a été acquise en exercice. L'application identique est bijective et constitue l'élément neutre pour la composition des bijections. Chaque bijection \(f\) admet sa bijection réciproque \(f^{-1}\) qui est son symétrique pour la loi de composition, ce qui permet de conclure que \((\Sn(X),\circ)\) est un groupe.
Si deux ensembles \(X\) et \(Y\) sont équipotents, étudier le groupe symétrique de l'un est équivalent à étudier celui de l'autre. En effet si \(f:X\rightarrow Y\) est une bijection alors l'application \(\varphi:{S}(X)\rightarrow{S}(Y)\) définie par \(\sigma\mapsto f\circ \sigma\circ f^{-1}\) est un isomorphisme de groupes. En particulier, si un ensemble est fini de cardinal \(n\), l'étude de son groupe symétrique peut toujours se faire à travers le groupe symétrique \(S_n\) de degré \(n\).
Le théorème de Cayley* Arthur Cayley était un mathématicien anglais. ci-dessous va plus loin et affirme que n'importe quel groupe peut être assimilé à un sous-groupe du groupe symétrique.
Tout groupe \((G,\diamond)\) est isomorphe à un sous-groupe de \(({S}(G),\circ)\).
Montrons que l'application \(\sigma:G\rightarrow S(G)\) définie par \(\sigma:g\mapsto\sigma_g\) qui associe à un élement du groupe \(g\) l'application \(\sigma_g:G\rg G\) définie par \(x\mapsto g\diamond x\), est un isomorphisme de \((G,\diamond)\) dans \((\text{Im}(\sigma),\circ)\). Assurons nous tout d'abord que \(\sigma\) est bien une permutation du groupe symétrique \(S(G)\).
Soit \(h\in G\), l'équation \(g\diamond x=h\) admettant l'unique solution \(g^{-1}\diamond h\), l'application \(\sigma_g\) est bijective et appartient donc à \(S(G)\). La loi \(\diamond\) étant associative, on a pour tout \((g,h,x)\in G^3\)
\begin{align*}
\sigma_{g\diamond h}(x)
&=(g\diamond h)\diamond x\\
&=g\diamond (h\diamond x)\\
&=g\diamond \sigma_h(x)\\
&=\sigma_g(\sigma_h(x))\\
&=(\sigma_g\circ\sigma_h)(x)
\end{align*}
Autrement dit \(\sigma_{g\diamond h}=\sigma_g\circ\sigma_h\), ce qui fait de l'application \(\sigma\) un morphisme de groupes surjectif sur son image \(\text{Im}(\sigma)\) qui est un sous-groupe de \(S(G)\). Reste à montrer qu'il est injectif. Son noyau \(\text{Ker}(\sigma):=f^{-1}({\Id}_G)\), autrement dit
\begin{align*}
\text{Ker}(\sigma)&=\{a\in G\mid \forall x\in G\ \ \sigma_a(x)=x\},\\
&=\{a\in G\mid \forall x\in G\ \ a\diamond x=x\}.
\end{align*}
Or \(\forall x\in G\ \ a\diamond x=x\) si et seulement si \(a=e\), le noyau est donc réduit au singleton \(\{e\}\) ce qui prouve l'injectivité. Finalement l'application \(\sigma\) est un isomorphisme.
Autrement dit, on peut étudier tous les groupes à travers le groupe symétrique, ce qui justifie l'intérêt qu'on lui porte. Nous allons donc nous concentrer sur le groupe symétrique et particulièrement sur le groupe \(\Sn_{n}\) de degré \(n\).
On code généralement une permutation \(\sigma\in{S}_n\) en organisant les \(n\) couples \((i,\sigma(i))\) qui constituent son graphe en colonnes pour former une matrice : sa première ligne contient les entiers de \(1\) à \(n\) dans l'ordre croissant, la seconde leurs images en vis-à-vis :
\begin{equation}
\sigma=\begin{pmatrix}
1&2&3&\cdots&n\\
\sigma(1)&\sigma(2)&\sigma(3)&\cdots&\sigma(n)
\end{pmatrix}
\end{equation}
On peut également utiliser la notation compacte \([\sigma(1),\sigma(2),\sigma(3),\ldots,\sigma(n)]\) de la séquence formée par les images de la permutation dans l'ordre croissant des valeurs de l'intervalle \(\ab{1}{n},\) à la manière d'une liste Python mais dont l'indexation débute à \(1.\)
À gauche une permutation de \(S_6\) sous forme matricielle et à droite sa forme compacte :
\[
\sigma=\begin{pmatrix}
1&2&3&4&5&6\\
2&5&1&4&6&3
\end{pmatrix}\qquad \sigma=[2,5,1,4,6,3].
\]
Décrivez toutes les permutations des groupes \(\Sn_{1}\) et \(\Sn_{2}\). En déduire que ces groupes sont commutatifs.
Le groupe \(\Sn_{1}\) ne contient que l'application identité, il est évidemment commutatif. Le groupe \(\Sn_{2}\) contient l'identité et la permutation \(\tau\) définie par \(\tau(1)=2\) et \(\tau(2)=1\). Par définition l'identité commute avec toutes les permutations, et toute permutation commute avec elle-même, \(\Sn_{2}\) est donc commutatif.
Pour tout entier \(n\geqslant 3\), le groupe \(\Sn_{n}\) n'est pas commutatif.
Comme \(n\geqslant 3\), il existe trois entiers distincts \(a\), \(b\) et \(c\) dans \(\ab{1}{n}\). On considère la permutation \(\sigma\) définie par \(\sigma(a):=b\), \(\sigma(b):=a\) et invariante en toute autre valeur, et la permutation \(\tau\) définie par \(\tau(a):=c\), \(\tau(c):=a\) et invariante en tout autre valeur. On a
\begin{align*}
\sigma\circ\tau(a)&=\sigma(c)=c\\
\tau\circ\sigma(a)&=\tau(b)=b.
\end{align*}
et par conséquent \(\sigma\circ\tau\not=\tau\circ\sigma\).
Ce dernier résultat est à ne pas perdre de vue. Le fait que ce groupe ne soit pas commutatif en général lui donne un intérêt tout particulier et le théorème de Cayley montre que l'étude du groupe symétrique et de ses sous-groupes permet indirectement d'étudier tous les groupes.
On considère le groupe \(S_3.\) Ses \(3!=6\) permutations sont notées (leurs décompositions en produits de cycles à supports disjoints sont données) :
\begin{align*}
a=\underbrace{[1,2,3]}_{\Id}\quad b=\underbrace{[1,3,2]}_{(2,3)}\quad c=\underbrace{[2,1,3]}_{(1,2)}\quad d=\underbrace{[2,3,1]}_{(1,2,3)}\quad f=\underbrace{[3,1,2]}_{(1,3,2)}\quad g=\underbrace{[3,2,1]}_{(1,3)}\quad
\end{align*}
Remplissez la table de Cayley interactive avec les \(36\) produits \(\sigma\,\sigma'\) avec \((\sigma,\sigma')\in S_3^2.\) Par exemple :
\[b\,d=(2,3)\,(1,2,3)=(1,3)=g\quad\text{et}\quad d\,b=(1,2,3)\,(2,3)=(1,2)=c.\]
Soit \(\sigma\in S_n\) avec \(n\geqslant 3\) et \(a\) et \(b\) deux entiers distincts de \(\ab{1}{n}\). On note \(\tau_{a,b}\) la permutation qui échange les deux valeurs \(a\) et \(b\) et laisse les autres valeurs fixes. Montrez que
\begin{equation}
\label{eq:compotau}
\sigma\circ\tau_{a,b}\circ\sigma^{-1}=\tau_{\sigma(a),\sigma(b)}.
\end{equation}
En déduire que le centre \(Z(\Sn_{n})\) du groupe \(\Sn_n\) est réduit au singleton \(\{{\Id}_n\}\) dès que \(n\geqslant 3\). Indications : si \(\sigma\in Z(\Sn_n)\), \(\sigma\) commute avec toutes les permutations de \(\Sn_n\), et en particulier avec celles du type \(\tau_{a,b}\), quelles que soient les valeurs de \(a\) et \(b\) avec \(a\neq b\).
Calculons l'image de \(\sigma(a)\) par la permutation \(\rho:=\sigma\circ\tau_{a,b}\circ\sigma^{-1}\). On a
\begin{align*}
(\sigma\circ\tau_{a,b}\circ\sigma^{-1})(\sigma(a))
&=\sigma\circ\tau_{a,b}(\sigma^{-1}(\sigma(a))\\
&=\sigma\circ\tau_{a,b}((\sigma^{-1}\circ\sigma)(a))\\
&=\sigma\circ\tau_{a,b}(a)\\
&=\sigma(b)
\end{align*}
Avec le même raisonnement, on montre que \((\sigma\circ\tau_{a,b}\circ\sigma^{-1})(\sigma(b))=\sigma(a)\). Si \(x\not\in\{a,b\}\), il est facile de voir que \((\sigma\circ\tau_{a,b}\circ\sigma^{-1})(x)=x\), ce qui achève de prouver \((\ref{eq:compotau})\).
Si \(\sigma\in Z(S_n)\), on peut appliquer \((\ref{eq:compotau})\) à n'importe quel couple de valeurs \((a,b)\) distinctes de l'intervalle \(\ab{1}{n}\), en particulier \((1,2)\) :
La loi de composition des applications se comporte de manière similaire à un produit de nombres (sans la commutativité), ainsi pour alléger les écritures, le symbole de composition des applications \(\circ\) est souvent omis dans les expressions. On parle également du produit \(\sigma\,\tau\) au lieu de la composition \(\sigma\circ\tau\) de \(\sigma\) et \(\tau\). Par conséquent, pour un entier naturel \(k\), la notation \(\sigma^k\) désigne la \(k\)-ème itérée de \(\sigma\), i.e.
\[
\sigma^k= \underbrace{\sigma\circ\sigma\circ\ldots\circ\sigma}_{k\ \text{termes}\ \sigma}
\]
et la notation \(\sigma^{-k}\) la \(k\)-ème itérée de la permutation inverse \(\sigma^{-1}\). Par convention \(\sigma^0\) désigne la permutation identité \(\Id{:}\,x\mapsto x\).
Orbites
On appelle ordre d'une permutation \(\sigma\in\Sn_n\) le plus petit entier naturel non-nul \(p\) tel que \(\sigma^p={\Id}\).
Il faut d'abord s'assurer que cet entier \(p\) existe pour justifier la définition. Montrons que l'ensemble \(\{k\in\N^*\mid \sigma^k={\Id}\}\) est une partie non-vide de \(\N.\) L'ensemble \(\{\sigma^k\mid k\in\N\}\) des itérés de \(\sigma\) est fini puisque c'est une partie de l'ensemble fini \(\Sn_n\). Ainsi la suite définie par \(k\mapsto \sigma^k\) n'est pas injective, i.e. il existe deux entiers \(k\) et \(l\) tels que \(k < l\) et \(\sigma^l=\sigma^k\) soit \(\sigma^{l-k}={\Id}\) avec \(l-k > 0\). On sait que toute partie non-vide de \(\N\) admet un plus petit élément ce qui achève la preuve de ce théorème.
Quelle est l'ordre de la permutation \(\sigma\) suivante ?
\begin{equation}
\sigma=\begin{pmatrix}
1 & 2 & 3 & 4 & 5\\
2 & 5 & 4 & 1 & 3
\end{pmatrix}
\end{equation}
L'observation du diagramme sagittal d'une permutation est toujours très instructif :
Diagramme sagittal de la permutation \(\sigma\).
On constate qu'il faut itérer \(5\) fois la permutation pour que chaque élément retrouve sa place : \(\sigma^5=\Id\), ce que l'on peut vérifier aisément par le calcul.
Soit \(\sigma\in\Sn_n\). La relation binaire \(\Rel{R}{\sigma}\) définie sur \(\ab{1}{n}\) par
\begin{equation}
x\Rel{R}{\sigma}y\ \iff\ \exists k\in\Z\quad y=\sigma^k(x).
\end{equation}
est une relation d'équivalence. La classe d'équivalence d'un élément \(x\in \ab{1}{n} \) est appelée orbite de \(x\) suivant \(\sigma\), on la note \(\orb_\sigma(x)\).
Démontrez ce théorème. Quelles sont les différentes orbites pour la permutation identité ?
Pour tout \(x\in\S_n\) on a \(x=\sigma^0(x)\) puisque \(\sigma^0=\Id,\) la relation est donc réflexive. Si \(y=\sigma^k(x)\) alors \(x=\sigma^{-k}(y),\) la relation est donc symétrique. Si \(y={\color{orange}\sigma(x)}\) et \(z=\sigma^{\ell}(y),\) alors \(z=\sigma^{\ell}({\color{orange}\sigma^{k}(x)})=\sigma^{\ell+k}(x)\) ce qui prouve la transitivité.
Tous les points de \(\ab{1}{n}\) étant fixes pour la permutation identité, il y a exactement \(n\) orbites formées par les singletons \(\{k\}\) pour \(k\in\ab{1}{n}.\)
Soit \(\sigma\in\Sn_n\) et \(\orb\) une orbite suivant \(\sigma\). Démontrez que l'application induite par \(\sigma\) sur \(\orb\) est une bijection.
La proposition suivante va nous permettre d'élaborer un algorithme pour construire l'orbite \(\orb_\sigma(x)\) d'un élément \(x\) de \(\ab{1}{n} \) suivant une permutation \(\sigma\in\Sn_n\).
Soit \(\sigma\in\Sn_n\) et \(\orb\) une orbite de cardinal \(p > 1\) suivant \(\sigma\). Alors
\begin{equation}
\label{eq:calculorb}
\forall x\in\orb\quad \orb=\{x,\sigma(x),\sigma^2(x),\ldots,\sigma^{p-1}(x)\}\quad\text{et}\ \ \sigma^p(x)=x.
\end{equation}
Soit \(x\in\ab{1}{n} \) tel que \(\orb=\orb_\sigma(x)\). Par définition \(\orb_\sigma(x)=\{\sigma^k(x)\mid k\in\Z\}\), c'est une partie de \(\ab{1}{n} \) donc finie elle aussi. Ainsi l'application définie par \(k\mapsto \sigma^k(x)\) n'est pas injective, i.e. il existe deux entiers relatifs \(k\) et \(l\) tels que \(k < l\) et \(\sigma^k(x)=\sigma^l(x)\), soit \(\sigma^{l-k}(x)=x\). L'ensemble \(\{e\in\N\mid \sigma^{e}(x)=x\}\) n'est donc pas vide et admet un plus petit élément \(p\).
Soit \(k\) un entier quelconque. Si \(q\) et \(r\) désignent respectivement le quotient et le reste de la division euclidienne de \(k\) par \(p\), i.e. \(k=qp+r\) avec \(0\leqslant r < p\), on a
\begin{align*}
\sigma^k(x)
&=\sigma^{r+qp}(x)\\
&=\sigma^{r+(q-1)p}(\sigma^p(x))\\
&=\sigma^{r+(q-1)p}(x)\\
&=\sigma^{r+(q-2)p}(\sigma^p(x))\\
&\ \ \vdots\\
&=\sigma^r(x)
\end{align*}
Tous les restes possibles étant compris entre \(0\) et \(p-1\), on a donc
\[\orb=\{\sigma^r(x)\mid 0\leqslant r < p\}.\]
Reste à montrer que \(|\orb|=p\), autrement dit que les \(\sigma^r(x)\) pour \(r\in[0,p[\) sont deux-à-deux distincts. Soit \(r\) et \(r'\) tels que \( 0\leqslant r\leqslant r' < p \) et \(s^r(x)=s^{r'}(x)\). On en déduit que \(\sigma^{r'-r}(x)=x\) et comme \(0\leqslant r'-r < p\) ceci impose que \(r'=r\).
Cette proposition montre que pour construire l'orbite d'un élément \(x\), il suffit d'itérer ses images par \(\sigma\) tant que la nouvelle image obtenue est différente de \(x\), ce qui revient en pratique à suivre les flèches dans le diagramme sagittal de la permutation.
L'application ci-dessous calcule les différentes orbites suivant une permutation \(\sigma\in S_n\) arbitraire. Elle calcule d'autres résultats qui vont être étudiés plus loin et qui sont compilés ici pour ne pas les disperser.
Les points fixes d'une permutation \(\sigma\) n'étant pas concernés par la permutation, il est naturel de se focaliser sur les valeurs qui sont effectivement mises en mouvement. Une permutation de \(S_n\) qui laisse \(k\) points fixes, est fondamentalement une permutation de \(S_{n-k}\) :
On appelle support d'une permutation \(\sigma\in\Sn_n\), le sous-ensemble de \(\ab{1}{n} \) noté \(\text{supp}(\sigma)\) des éléments de \(\ab{1}{n} \) qui ne sont pas fixés par \(\sigma\), i.e.
\begin{equation}
\text{supp}(\sigma):=\{x\in \ab{1}{n} \mid\sigma(x)\not=x\}.
\end{equation}
(1) Le support de la permutation \(\sigma=[3,{\color{darkgray}2},8,1,6,9,{\color{darkgray}7},4,5,12,{\color{darkgray}11},10]\) est
\[\text{supp}(\sigma)=\{1,3,8,4,5,6,9\}\]
puisque \(2\), \(7\) et \(11\) sont des points fixes.
(2) Pour tout \(n\in\N,\) le support de la permutation identique \(\Id\) est l'ensemble vide \(\varnothing\) puisque tous les points sont fixes.
Soit \(n\) un entier tel que \(n\geqslant 2\). Calculez le support de la permutation \(\sigma\in\Sn_{n}\) définie par \(\sigma(k):=k+1\) si \(k < n\) et
\(\sigma(n):=1\). Soit \(a\) et \(b\) deux éléments distincts de \(\ab{1}{n} \). Calculez le support de la permutation \(\sigma\in\Sn_{n}\) définie par \(\sigma(a):=b\) et \(\sigma(b):=a\) et qui laisse fixe tous les autres entiers.
Cycles
On appelle cycle toute permutation \(\sigma\in\Sn_n\) telle qu'il existe une unique orbite \(\orb\) qui n'est pas un singleton. Dans ce cas, \(\text{supp}(\sigma)=\orb\) et \(\#\orb\) est appelé la longueur du cycle. Un cycle de longueur \(p\) est appelé un p-cycle et un 2-cycle est appelé une transposition.
La permutation \(\sigma=[{\color{#FD4}3},{\color{darkgray}2},{\color{#FD4}8},{\color{#FD4}1},{\color{#88F}6},{\color{#88F}9},{\color{darkgray}7},{\color{#FD4}4},{\color{#88F}5}]\) n'est pas un cycle mais en contient deux : un \(4\)-cycle et un \(3\)-cycle.
Démontrez que toute transposition \(\tau\) est une involution, c'est-à-dire vérifie \(\tau^2={\Id}.\)
À ce stade, nous savons que la restriction d'une permutation \(\sigma\) à une orbite \(\orb{}\) est une bijection (cf. exercice), c'est donc une permutation définie sur l'ensemble \(\orb{}\). En notant \(x_1\) un représentant de \(\orb{}\) et en définissant par récurrence \(x_{k+1}:=\sigma(x_k)\), l'assertion \((\ref{eq:calculorb})\) montre que cette restriction est de la forme
Ceci explique pourquoi on a qualifié de cycle une telle permutation (on déplace tous les étudiants d'une rangée d'une place sur leur gauche et le dernier étudiant se place en première position sur la rangée). On en déduit qu'un \(p\)-cycle opère un décalage circulaire sur les éléments de son orbite et laisse fixes les \(n-p\) éléments restants. Ceci justifie que l'on note un \(p\)-cycle \(\sigma\) par le \(p\)-uplet
\[(x_1,x_2,\ldots,x_p)\]
qui le caractérise puisque \(\sigma(x_i)=x_{i+1}\) pour \(i\in\ab{1}{p-1}\) et \(\sigma(x_p)=x_1\). Une transposition \((x_i,x_j)\) est parfois notée \(\tau_{x_i,x_j}\).
Soit \((\sigma_i)_{i\in I}\) une famille de cycles d'un ensemble fini \(X\) de supports \(Y_i\) deux-à-deux disjoints et de réunion \(Y\). Alors
Les \(\sigma_i\) commutent deux-à-deux ce qui permet de définir leur produit \[\sigma:=\prod_{i\in I}\sigma_i.\]
Le produit \(\sigma\) coïncide avec \(\sigma_i\) sur \(Y_i\) et avec l'identité \({\Id}_X\) sur \(X\setminus Y.\)
Les \(Y_i\) sont les orbites suivant \(\sigma\) qui ne sont pas réduites à un élément.
On déduit de l'étude menée le théorème suivant, qui est l'homologue du théorème fondamental de l'arithmétique affirmant que tout entier naturel se décompose de manière unique, à l'ordre près des facteurs, en produit de facteurs premiers.
Toute permutation \(\sigma\) non identique d'un ensemble fini \(X\) se décompose de manière unique, à l'ordre près des facteurs, en produit de cycles à supports deux-à-deux disjoints.
La première propriété du lemme ci-dessus est très importante. L'analogie permanente entre le calcul sur les nombres et sur les permutations (produit, décomposition, etc.) peut nous fourvoyer car le produit de nombres (entiers, réels, complexes, etc.) est commutatif alors que la composition des applications ne l'est pas ! Il est en effet tentant d'écrire par réflexe \({\color{red}(\sigma\,\tau)^2=\sigma^2\,\tau^2}\) où \(\sigma\) et \(\tau\) sont deux permutations, alors que
\begin{align*}
(\sigma\,\tau)^2 &=(\sigma\,\tau)\,(\sigma\,\tau)\\
&=\sigma\,({\color{orange}\tau\,\sigma})\,\tau
\end{align*}
et qu'en général \({\color{orange}\tau\,\sigma\neq\sigma\,\tau}\), sauf si les supports des permutations \(\tau\) et \(\sigma\) sont disjoints.
Les différents résultats obtenus montrent que l'algorithme que nous avons appliqué pour calculer les différentes orbites détermine également les différents cycles puisque nous avons calculé chaque orbite en itérant la permutation \(\sigma\).
Les cycles d'une décomposition d'une permutation en produit de cycle permutent-ils nécessairement ?
La réponse est non, on peut tout à fait décomposer une permutation en produit de cycles sans qu'ils soient nécessairement à supports disjoints. Considérons le contre-exemple suivant :
\[
\sigma=
\begin{pmatrix}
1 & 2 & 3\\
1 & 3 & 2
\end{pmatrix}
\]
On vérifie aisément que \(\sigma=(1,2)(2,3,1)=(2,3)\) alors que \((2,3,1)(1,2)=(1,3)\).
Le lemme suivant va nous permettre de démontrer un résultat bien connu du lecteur masqué par le vocabulaire des permutations : on peut réorganiser les livres de sa bibliothèque comme on le souhaite en ne permutant jamais plus de deux livres à la fois (ce qui est bien pratique quand on n'a que deux mains).
Tout \(p\)-cycle \((x_1,x_2,\ldots,x_p)\) sur un ensemble \(X\) se décompose en produit de transpositions, par exemple
\begin{equation}
\label{eq:prodtrans}
(x_1,x_2,\ldots,x_p)=\prod_{i=1}^{p-1}(x_i,x_{i+1}).
\end{equation}
Notons \(\sigma:=(x_1,x_2,\ldots,x_p)\) et \(\rho\) le produit des transpositions \((x_i,x_{i+1})\) défini en \((\ref{eq:prodtrans})\).
Montrons que \(\sigma=\rho\). Trivialement tout élément \(x\in X\) qui n'appartient pas au support \(\{x_1,\ldots,x_p\}\) de \(\sigma\) est laissé fixe par \(\sigma\) et \(\rho\). Reste à traiter les éléments \(x_i\) dans le support de \(\sigma\). Si \(i < p\), on a \(\sigma(x_i)=x_{i+1}\), mais
\begin{align*}
\rho(x_i)&=\left(\prod_{j=1}^{i}(x_j,x_{j+1})\right)
(x_{i-1},x_{i}){\color{#FF8}(x_i,x_{i+1})}\left(\prod_{j=i+1}^{p}(x_j,x_{j+1})\right)(x_i) \\
\rho(x_i)&=\left(\prod_{j=1}^{i}(x_j,x_{j+1})\right)
(x_{i-1},x_{i}){\color{#FF8}(x_i,x_{i+1})}(x_i) \\
\rho(x_i)&=\left(\prod_{j=1}^{i}(x_j,x_{j+1})\right)
(x_{i-1},x_{i})(x_{i+1}) \\
&=x_{i+1} \\
\end{align*}
Si \(i=p\) alors \(\sigma(x_p)=x_1\), mais (la preuve suivante est informelle, formalisez là avec une récurrence finie)
\begin{align*}
\rho(x_p)&=\left(\prod_{i=1}^{p-2}(x_i,x_{i+1})\right)
{\color{#FF8}(x_{p-1},x_{p})}(x_p) \\
&=\left(\prod_{i=1}^{p-3}(x_i,x_{i+1})\right)
{\color{#FF8}(x_{p-2},x_{p-1})}(x_{p-1}) \\
&=\left(\prod_{i=1}^{p-4}(x_i,x_{i+1})\right)
{\color{#FF8}(x_{p-3},x_{p-2})}(x_{p-2}) \\
&=\qquad\vdots\\
&={\color{#FF8}(x_1,x_2)}(x_2)\\
&=x_1 \\
\end{align*}
Il n'y a pas unicité de la décomposition en produit de transpositions, celle fournie en
\((\ref{eq:prodtrans})\) est un cas particulier simple à obtenir. En revanche la parité du nombre de transpositions est constant.
Toute permutation d'un ensemble fini \(X\) de cardinal \(n\geqslant 2\) se décompose en produit de transpositions.
C'est vrai pour la permutation identité \(\Id_X\) puisque si \(n\geqslant 2\), on peut trouver deux éléments distincts \(a\) et \(b\) de \(X\) et écrire \(\Id_X=(a,b)(a,b)\). Pour toute autre permutation, nous savons qu'elle se décompose en produit de cycles et le lemme ci-dessus permet de conclure.
Démontrez que si \(\sigma\) est un \(p\)-cycle, alors \(\sigma^p={\Id}\). Quelle est l'inverse d'un \(p\)-cycle ?
Le théorème précédent affirmait que l'on pouvait réorganiser sa bibliothèque en ne permutant que deux livres à la fois, le théorème suivant affirme que l'on peut encore y arriver si ces deux livres sont toujours côte à côte.
Toute transposition se décompose en produit de transpositions de la forme \((i,i+1)\).
Soit \(i\) et \(j\) dans \(\ab{1}{n} \) avec \(j \neq i+1\), sinon il n'y a rien à prouver. Montrons que
\begin{equation*}
(i,j)={\color{#88F}(j-1,j)}{\color{#FFF}(i,j-1)}{\color{#88F}(j-1,j)}
\end{equation*}
On note \(\pi\) la permutation produit ci-dessus. On a :
\begin{align*}
\pi(i)&={\color{#88F}(j-1,j)}{\color{#FFF}(i,j-1)}{\color{#88F}(j-1,j)}(i)\\
&={\color{#88F}(j-1,j)}{\color{#FFF}(i,j-1)}(i)\\
&={\color{#88F}(j-1,j)}(j-1)\\
&=j
\end{align*}
On obtient de façon similaire \(\pi(j)=i\). Un raisonnement par récurrence finie nous permet d'obtenir le résultat en répétant la même décomposition pour \((i,j-1)\) de proche en proche pour conclure.
Le groupe \(\Sn_n\) est engendré par la famille de transpositions \(\{(i,i+1)\}_{i=1}^{n-1}.\)
Il suffit d'appliquer les résultats précédent. Toute permutation se décompose en produit de cycles, eux mêmes se décomposent en produit de transpositions qui elles-mêmes se décomposent en produit de transpositions de la forme \((i,i+1)\).
Démontrez que l'ordre \(p\) d'une permutation \(\sigma\) est le plus petit commun multiple des longueurs des cycles à supports disjoints de cette permutation. En déduire que pour tout entier \(k\in\N\), on a \(\sigma^k=\sigma^r\) où \(r\) est le reste de la division euclidienne de \(k\) par \(p\). Si \((\sigma_i)_{i=1}^{k}\) est la décomposition en produit de cycles à supports disjoints d'ordres respectifs \(p_i\), montrez que
\[\sigma^k = \prod_{i=1}^k\sigma_i^{r_i}\]
où \(r_i\) désigne le reste de la division euclidienne de \(r\) par \(p_i\).
Peut-on réorganiser sa commode (un empilement de tiroirs) comme on le souhaite en ne réalisant que des échanges entre le contenu de tiroirs adjacents ?
Soit \(n\) et \(p\) deux entiers naturels tels que \(0\leqslant p\leqslant n\). Combien le groupe \({S}_n\) possède-t-il de \(p\)-cycles ?
Permutations et tris comparatifs
On se donne une liste* Une séquence. \(L\) de \(n\) valeurs d'ensemble d'indexation \({[n]}:=\ab{1}{n}\), dans un ensemble totalement ordonné \((X,\preceq)\). On cherche à trier les \(n\) valeurs \(L[i],\ i\in{[n]}\) de cette liste dans l'ordre croissant.
Pour étudier un algorithme basé sur des comparaisons entre éléments de \(X\), on peut toujours supposer que \(X={[n]}\) et qu'il est muni de l'ordre naturel \(\leq\). En effet, l'ordre sur \(X\) étant total, on peut toujours numéroter les \(n\) éléments \(x_1,x_2,\ldots,x_n\) de la liste \(L\) de sorte que
\[
\forall (i,j)\in{[n]}^2 \quad (i \leqslant j)\ \then\ (x_i \preceq x_j).
\]
ce qui définit une application croissante*Un morphisme d'ensembles ordonnés \(x:{[n]}\to L({[n]}),\) où \(L({[n]})\) est l'image de l'application \(L,\) autrement dit, l'ensemble des valeurs de la liste. En triant les valeurs entières, on trie donc les éléments de la liste à travers ce morphisme. Pour illustrer le propos, tout algorithme de tri comparatif opère de la même manière pour trier la liste \(L=[3,9,4,2]\) que pour trier la liste \[L=[\underset{3}{2},\underset{9}{4},\underset{4}{3},\underset{2}{1}],\]
le morphisme en question de \(\ab{1}{4}\rg\{3,9,4,2\}\) étant défini par \(1\mapsto 2\), \(2\mapsto 3\), \(3\mapsto 4\) et \(4\mapsto 9\). La valeur importe peu, ce sont les positions relatives des valeurs pour la relation d'ordre qui déterminent le comportement de l'algorithme.
Par conséquent, on peut supposer que la liste \(L\) de longueur \(n\) contient exactement les \(n\) entiers de \(1\) à \(n\), autrement dit \(L\) code explicitement une permutation du groupe symétrique \(\Sn_n\) :
Pour trier \(L\), on suppose que l'on dispose d'une opération \(i\overset{L}{\rightleftharpoons} j\) qui échange le contenu des cellules d'indices \(i\) et \(j\) de la liste \(L\). Cette opération est réalisée par l'algorithme suivant :
ALGORITHME Echanger(@L,i,j):
aux ← L[i]
L[i] ← L[j]
L[j] ← aux
On connaît évidemment le résultat des courses puisque la liste triée est la liste \([1,2,\ldots,n]\), c'est-à-dire la permutation identité. Mais ce n'est pas tant le résultat du tri qui nous motive ici, que la manière de le réaliser. L'échange \(i\overset{L}{\rightleftharpoons} j\) définit implicitement la transposition \((L[i],L[j])\) et un algorithme de tri comparatif opère en une séquence finie d'échanges, donc de transpositions. Notons \((\tau_k)_{k=1}^t\) les \(t\) échanges réalisés pour trier la liste \(L\). On vient de montrer que
\begin{align*}
\tau_t\,\tau_{t-1}\,\ldots\,\tau_2\,\tau_1\, L &= {\Id},\\
L &= {\Id}\,(\tau_t\,\tau_{t-1}\,\ldots\,\tau_2\,\tau_1)^{-1},\\
L &= \tau_1\,\tau_2\,\ldots\,\tau_{t-1}\,\tau_t \quad\text{car}\ (s\,t)^{-1}=t^{-1}\,s^{-1}\ \text{et}\ \tau_i^{-1}=\tau_i.
\end{align*}
Nous venons de décomposer la permutation \(L\) en produit de transpositions. Chaque algorithme de tri comparatif in situ*qui échange les valeurs dans la liste constitue donc une preuve constructive que toute permutation se décompose en un produit de transpositions. On comprend mieux à présent pourquoi la décomposition d'une permutation en produit de transpositions n'a rien d'unique vu la diversité des algorithmes de tris comparatifs.
L'algorithme du tri par propagation également appelé tri à bulles, réalise le tri d'une liste uniquement avec des échanges du type \(i\rightleftharpoons i+1\). Le principe est simple, pour toutes les valeurs \(k\) allant de \(n\) à \(2\), on balaie la liste \(L\) de \(i\leftarrow 1\) à \(k\) en faisant l'échange \(i\rightleftharpoons i+1\) si \(L[i+1] \preceq L[i]\).
La grande variété des preuves/algorithmes de tris est justifiée par la recherche de décompositions en produits de transpositions qui minimisent le nombre de comparaisons et/ou d'échanges entre éléments de la liste.
Signature
Dans la suite, \(X\) désigne un ensemble fini de cardinal \(n\).
On appelle signature d'une permutation \(\sigma\in\Sn(X)\) l'entier
\begin{equation}
\epsilon(\sigma):=(-1)^{n-m}
\end{equation}
où \(m\) est le nombre d'orbites suivant \(\sigma\). Si \(\epsilon(\sigma)=+1\), on dit que \(\sigma\) est une paire et impaire si \(\epsilon(\sigma)=-1\).
La permutation identité génère \(n\) orbites puisque tous les points sont fixes, donc \(\epsilon({\Id}_X)=(-1)^{n-n}=1\). Une transposition \(\tau\) laisse \(n-2\) points fixes et crée une orbite de cardinal \(2\), il y a donc au total \(n-1\) orbites, d'où \(\epsilon(\tau)=(-1)^{n-(n-1)}=-1\). Un \(p\)-cycle \(\sigma\) laisse \(n-p\) points fixes et crée une unique orbite de taille \(p\), il y a donc \(n-p+1\) orbites, donc \(\epsilon(\sigma)=(-1)^{n-(n-p+1)}=(-1)^{p-1}\).
Soit \(\sigma\) une permutation et \(\tau\) une transposition de \(S(X)\), alors
\begin{equation}
\epsilon(\sigma\,\tau)=-\epsilon(\sigma).
\end{equation}
Notons \(\tau_{a,b}\) cette transposition et \(\sigma':=\sigma\tau_{a,b}\). On cherche à savoir comment les orbites suivant \(\sigma\) vont être perturbées par la transposition \(\tau_{a,b}\). La restriction de \(\tau_{a,b}\) aux orbites qui ne contiennent ni \(a\) ni \(b\) est l'identité, les seules orbites qui sont perturbées par \(\tau_{a,b}\) sont donc uniquement celles qui contiennent \(a\) ou \(b\). Deux cas de figure se présentent, soient \(a\) et \(b\) sont sur la même orbite \(\orb\), soit sur deux orbites distinctes \(\orb\) et \(\orb'\) puisque les orbites suivant \(\sigma\) forment une partition de l'ensemble \(X\) :
À gauche : \(a\) et \(b\) sont sur la même orbite \(\orb\). À droite : \(a\) et \(b\) sont sur deux orbites \(\orb\) et \(\orb'\) distinctes.
Supposons dans un premier temps que \(\{a,b\}\subseteq\orb\) et notons \(p:=|\orb|\geqslant 2\). Dans ce cas \(a\) (et \(b\)) est un représentant de l'orbite \(\orb\) donc
\[\orb=\orb(a)=\{a,\sigma(a),\ldots,\sigma^{p-1}(a)\}\quad\text{et}\ \ \sigma^p(a)=a.
\]
Puisque \(b\in\orb(a)\), \(b=\sigma^q(a)\) avec \(0 \lt q\leqslant p\). Calculons les itérés successifs de \(a\) par la permutation \(\sigma'\). On a
\begin{align*}
\sigma'(a)
&=\sigma(\tau(a)),\\
&=\sigma(b),\\
&=\sigma^{q+1}(a).
\end{align*}
et \(\sigma'(\sigma^{q+1}(a))=\sigma(\tau(\sigma^{q+1}(a)))\), mais \(\sigma^{q+1}(a)\not\in\{a,b\}\), or la restriction de la transposition \(\tau_{a,b}\) à \(X\setminus\{a,b\}\) est l'identité, donc
\[\sigma'(\sigma^{q+1}(a))=\sigma^{q+2}(a)\]
et de proche en proche on obtient montre que l'orbite de \(a\) selon \(\sigma'\) est
\[a,\;\sigma^{q+1}(a),\;\sigma^{q+2}(a),\;\ldots,\;\sigma^{p-2}(a),\;\sigma^{p-1}(a),\; a.\]
Tandis que les itérés de \(b\) selon \(\sigma'\) sont
\[b,\;\sigma(b),\;\sigma^2(b),\;\ldots,\;\sigma^{q-1}(b),\;b.\]
Autrement dit, l'orbite \(\orb\) a été séparée en deux orbites.
Dans l'autre cas (à droite sur la figure), on a
\begin{align*}
\orb&=\{a,\sigma(a),\sigma^2(a),\ldots,\sigma^{p-1}(a)\},\\
\orb'&=\{b,\sigma(b),\sigma^2(b),\ldots,\sigma^{q-1}(b)\}.\\
\end{align*}
Si on calcule les itérés de \(a\) pour \(\sigma'\), on obtient
\[a,\;\sigma(b),\;\sigma^2(b),\;\ldots,\sigma^{q-1}(b),\;b,\;\sigma(a),\;\sigma^2(a),\;\ldots,\;\sigma^{p-1}(a),\;a.\]
Autrement dit les orbites \(\orb\) et \(\orb'\) ont fusionné. Dans les deux cas le nombre d'orbites suivant \(\sigma'\) est différent du nombre d'orbites suivant \(\sigma\) d'une unité ce qui change donc le signe de la signature et permet de conclure.
Si \(\sigma\in\Sn(X)\) est le produit de \(k\) transpositions, alors \(\epsilon(\sigma)=(-1)^k\).
L'application signature \(\epsilon:\Sn(X)\rightarrow\{-1,1\}\) est un morphisme du groupe symétrique \((\Sn(X),\circ)\) dans le groupe multiplicatif \((\{-1,1\},\times)\).
Il faut donc déduire de ce corollaire que la signature d'un produit (au sens de la composition des applications) de permutations est le produit (au sens des nombres entiers) de leurs signatures.
Le noyau du morphisme \(\epsilon\) est un sous-groupe normal de \(\Sn(X)\) appelé groupe alterné. On le note \(A(X)\) ou parfois \({\mathfrak A}(X)\def\A{{A}}\).
Soit \(\tau\) une transposition. L'application de \(\A(X)\) dans \(\Sn(X)\setminus\A(X)\) définie par \(\sigma\mapsto\tau\sigma\) est une bijection et comme ces deux ensembles constituent une partition de \(\Sn(X)\) qui est de cardinal \(n!\), on a nécessairement
Autrement dit, il y a autant de permutations paires que de permutations impaires. Dans le cas où \(\Sn(X)=\Sn_{n}\), le sous-groupe alterné est noté \(A_n\) ou \({\mathfrak A}_n\) et on l'appelle groupe alterné de degré n.
Soit \(\sigma\in\Sn_n\). Démontrez que
\begin{equation}
\epsilon(\sigma)=\prod_{\{i,j\}\in {\mathscr P}_2(\ab{1}{n} )}\frac {\sigma (j)-\sigma (i)}{j-i}
\end{equation}
où \({\mathscr P}_2(\ab{1}{n} )\) désigne l'ensemble des paires d'éléments de \(\ab{1}{n} \).
Indication : l'application définie par \(\{i,j\}\mapsto\{\sigma(i),\sigma(j)\}\) est une permutation sur \({\mathscr P}_2(\ab{1}{n} )\).
Démontrez que toutes les décompositions en produits de transpositions d'une permutation ont même parité.
Conjugaisons d'une permutation
Deux permutations \(\sigma\) et \(\sigma'\) sont conjuguées s'il existe une permutation \(\rho\) telle que \(\sigma'= \rho\,\sigma\,\rho^{-1}\). Cela signifie que l'on peut réaliser la permutation \(\sigma'\) à travers la permutation \(\sigma\) au prix de deux traductions réciproques. La relation de conjugaison est définie pour tout groupe, nous savons déjà qu'il s'agit d'une relation d'équivalence.
Montrez que la classe de conjugaison de la permutation identique \({\Id}\) est réduite à \({\Id}\) quel que soit le groupe symétrique.
Montrez que les transpositions \((1,2)\) et \((1,3)\) sont conjuguées dans \(\Sn_3\).
Soit \(\sigma=(x_1,x_2,\ldots,x_p)\) un \(p\)-cycle et \(\rho\) une permutation. La permutation conjuguée \(\rho\,\sigma\,\rho^{-1}\) de \(\sigma\) par \(\rho\) est le \(p\)-cycle :
\begin{equation}
\label{eq:conjuguecycle}
(\rho(x_1),\rho(x_2),\ldots,\rho(x_p)).
\end{equation}
appelé cycle conjugué de \(\sigma\).
On va calculer l'image de chaque élément de \(X\) par les deux applications à gauche et droite de l'égalité (\ref{eq:conjuguecycle}). Pour cela on va partitionner l'ensemble \(X\) en deux classes, l'ensemble \(Y:=\{\rho(x_i)\such i\in\ab{1}{p}\}\) et son complémentaire \(X\setminus Y\).
Calculons tout d'abord l'image des éléments \(\rho(x_i)\), \(i\in\ab{1}{p}\) par les deux permutations de part et d'autre de l'égalité \((\ref{eq:conjuguecycle})\) :
\begin{align}
\rho(x_1,x_2,\ldots,x_p)\rho^{-1}(\rho(x_i))
&=\rho(x_1,x_2,\ldots,x_p)(x_i)\\
&=\begin{cases}
\rho(x_{i+1})&\text{si}\ i < p,\\
\rho(x_1)&\text{si}\ i = p.
\end{cases}
\end{align}
D'autre part,
\begin{align}
(\rho(x_1),\rho(x_2),\ldots,\rho(x_p))(\rho(x_i))
&=\begin{cases}
\rho(x_{i+1})&\text{si}\ i < p,\\
\rho(x_1)&\text{si}\ i = p.
\end{cases}
\end{align}
On passe aux éléments \(x\in X\setminus Y\). On remarque que \(\forall i\in\ab{1}{p} \ \rho^{-1}(x)\not=x_i\) sans quoi \(x=\rho(x_i)\) ce qui contredit \(x\in X\setminus Y\), donc \(\rho^{-1}(x)\) n'appartient pas au support du cycle \((x_1,x_2,\ldots,x_p)\), il est donc un point fixe de ce cycle :
\begin{align*}
\rho(x_1,x_2,\ldots,x_p)\rho^{-1}(x)=\rho(\rho^{-1}(x))=x.
\end{align*}
D'autre part \(x\) est fixe pour le cycle \((\rho(x_1),\rho(x_2),\ldots,\rho(x_p))\) puisque \(x\not\in Y\), donc
\begin{align*}
(\rho(x_1),\rho(x_2),\ldots,\rho(x_p))(x)=x
\end{align*}
Soit \(\sigma\) et \(\rho\) deux permutations. La décomposition en produits de cycles à supports disjoints de la conjuguée \(\rho\,\sigma\,\rho^{-1}\) de \(\sigma\) est le produit des cycles conjugués de la décomposition en produit de cycles à supports disjoints de \(\sigma\).
En effet, notons \((c_i)_{i=1}^k\) les \(k\) cycles de la décomposition de \(\sigma\). Alors
\begin{align*}
\rho\sigma\rho^{-1}&=\rho\,{\color{#88F}c_1\,c_2\,c_3\,\ldots\,c_{k-1}\,c_k}\,\rho^{-1}\\
&=\rho\,{\color{#88F}c_1}\,(\rho^{-1}\,\rho)\,{\color{#88F}c_2}\,(\rho^{-1}\,\rho)\,{\color{#88F}c_3}\,\rho^{-1}\ldots\rho\,{\color{#88F}c_{k-1}}\,(\rho^{-1}\,\rho)\,{\color{#88F}c_k}\,\rho^{-1}\\
&=(\rho\,{\color{#88F}c_1}\,\rho^{-1})\,(\rho\,{\color{#88F}c_2}\,\rho^{-1})\,(\rho\,{\color{#88F}c_3}\,\rho^{-1})\ldots(\rho\,{\color{#88F}c_{k-1}}\,\rho^{-1})\,(\rho\,{\color{#88F}c_k}\,\rho^{-1})\\
\end{align*}
Soit \(\sigma\) une permutation et \(c_1\,c_2\ldots\,c_k\) sa décomposition en produit de cycles à supports disjoints de longueurs respectives \(p_i:=|c_i|\) croissantes. Le \(k\)-uplet \((p_1,p_2,\ldots,p_k)\) est appelé type de la permutation \(\sigma\).
Soit \(\sigma\) une permutation de type \((p_1,p_2,\ldots,p_k)\). Alors son ordre est le plus petit commun multiple des \(p_i\).
Notons \(n_i\) le nombre d'orbites de cardinal \(i\in\ab{1}{n} \) suivant la permutation \(\sigma\in\Sn_n.\) Les orbites formant une partition de \(\ab{1}{n} \), la formule de sommation nous donne
D'autre part, le type \((p_1,p_2,\ldots,p_k)\) de la permutation \(\sigma\) contient la taille de chaque orbite qui n'est pas réduite à un élément. Autrement dit le nombre \(n_1\) de points fixes de la permutation \(\sigma\), c'est-à-dire le nombre d'orbites réduites à un singleton est donné par
Ceci justifie que le type d'une permutation se dispense de faire apparaître les longueurs 1 des orbites réduites à un élément.
Nous avons vu que la permutation conjuguée d'un cycle par une permutation \(\rho\) est le cycle constitué des images des éléments du cycle par \(\rho\), cf. \((\ref{eq:conjuguecycle})\). Par conséquent :
Deux permutations sont conjuguées si et seulement si elles ont même type.
On en déduit immédiatement que le nombre de types de permutations du groupe \(\Sn_n\) distincts est égal au nombre de façons possibles d'écrire l'entier \(n\) comme la somme d'une suite croissante d'entiers non-nuls. Une telle somme est qualifiée de partition d'un entier. Par exemple, pour \(n=4\), on vérifie aisément que l'on a exactement les \(5\) partitions suivantes :
Le type vide est celui de la permutation identité.
Le nombre de classes de conjugaison du groupe \({S}_n\) est égal au nombre de partitions de l'entier \(n\).
Combien y-a-t-il de partitions de l'entier \(n=5\) ?
Déterminez les classes de conjugaison des groupes \(\Sn_3\) et \(\Sn_4\).
Soit \(\sigma\in{S}_n\) une permutation, \(k_1\) le nombre de ses orbites de taille \(1\) et \(k_p,\ \ {p\in\ab{2}{n}}\) le nombre de \(p\)-cycles dans sa décomposition en produit de cycles à supports disjoints. Montrez que \(\sigma\) a
\[\frac{n!}{\displaystyle\prod_{p=1}^{n}\left(p^{k_p}k_p!\right)}\]
conjugués.
Soit \(n\) et \(k\) deux entiers naturels non-nuls. Le nombre \(p(n,k)\) de partitions de l'entier \(n\) en \(k\) parties est
\begin{equation}
\label{rec:pnk}
p(n,k):=\begin{cases}
p(n–1, k–1) + p(n–k, k) &\text{si}\ 1 < k < n,\\
1&\text{si}\ k=1\ \text{ou}\ k=n,\\
0&\text{si}\ k > n.
\end{cases}
\end{equation}
En corollaire, on sait à présent que le nombre de partitions \(p(n)\) d'un entier \(n > 0\), c'est-à-dire le nombre de type différents de permutations est égal à
\begin{equation}
p(n)=\sum_{k=1}^np(n,k).
\end{equation}
Soit \(\sigma\in\Sn_n\) une permutation. Tout couple
\((i,j)\in\ab{1}{n}^2\) tel que
\begin{equation}
(i < j)\ \wedge\ (\sigma(i) > \sigma(j))
\end{equation}
est appelé inversion de \(\sigma\in\Sn_n\).
Soit \(n\in\N\). Vérifiez que le nombre de couples \((i,j)\in\ab{1}{n}^2\) tels que \(i \lt j\) est égal à
\begin{equation}
\frac{n(n-1)}{2}.
\end{equation}
On calcule donc le cardinal de l'ensemble \(\{(i,j)\in\ab{1}{n}^2\such i\lt j\}\) :
\begin{align*}
\#\{(i,j)\in\ab{1}{n}^2\such i\lt j\}
&=\#\left(\bigsqcup_{j=1}^{n}\{i\in\ab{1}{n}\such i \lt j\}\right)\\
&=\#\left(\bigsqcup_{j=1}^{n}\{i\in\ab{1}{j-1}\}\right)\\
&=\sum_{j=1}^n\#\{i\in\ab{1}{j-1}\}\\
&=\sum_{j=1}^{n}(j-1)\\
&=\frac{n(n-1)}{2}
\end{align*}
Le nombre total d'inversions des permutations du groupe \(S_n\) est égal à
\begin{equation}
n!\ \frac{n(n-1)}{4}
\end{equation}
Soit \(\sigma\) une permutation de \({\frak S}_n\). Notons \(\overline{\sigma}\) la permutation miroir de \(\sigma\) définie par
\[
\forall i\in\ab{1}{n} ,\quad\overline{\sigma}(i):=\sigma(n-i+1).
\]
Par exemple si \(\sigma=[1\;3\;2]\) alors \(\overline{\sigma}=[2 \;3\;1]\). Par construction, un couple \((i,j)\) est une inversion de \(\sigma\) si et seulement si le couple \((n-j+1,n-i+1)\) n'est pas une inversion de sa permutation miroir \(\overline{\sigma}\) et réciproquement.
Autrement dit, tout couple \((i,j)\) tel que \(i\lt j\) est, soit une inversion de \(\sigma\), soit une inversion de \(\overline{\sigma}\), il y a donc \(\frac{n(n-1)}{2}\) inversions (voir exercice ci-dessus) réparties entre \(\sigma\) et \(\overline{\sigma}\). Si on somme sur tous \(\sigma\in S_n\), on a donc au total
\(n!\,\frac{n(n-1)}{2}\) inversions, mais chaque permutation de \(S_n\) a été comptée deux fois puisque l'opération miroir est une bijection de \(S_n\). Il y a donc finalement
\[n!\ \frac{n(n-1)}{4}.\]
inversions au total.
Une permutation \(\sigma\in S_n\) est appelée dérangement si et seulement si
\begin{equation}
\forall i\in\ab{1}{n}\quad \sigma(i)\neq i.
\end{equation}
Le nombre de dérangements du groupe \(S_n\), noté \(!n\), est égal à
\begin{equation}
\label{eq:nbder}
n! \sum_{k=0}^{n} \frac{(-1)^k}{k!}
\end{equation}
Soit \(n\) et \(k\) deux entiers naturels tels que \( 0\leqslant k\leqslant n \) avec \( n\geqslant 1 \). On définit \( F_{n,k} \) comme le nombre de permutations de \( S_n \) ayant \( k \) points fixes, c'est-à-dire
\begin{equation}
F_{n,k}:=\#\big\{\sigma\in S_n\such \exists I\in\mathscr{P}_k(\ab{1}{n})\ \forall i\in I\ \sigma(i)=i\big\}.
\end{equation}
On pose \( F_{0,0}:=1 \) et \( !n:=F_{n,0} \), où \( !n \) désigne le nombre de dérangements.
Dressez la liste de toutes les permutations de \(S_3\) et en déduire la valeur de \( F_{3,0} \), \( F_{3,1} \), \( F_{3,2} \) et \( F_{3,3} \).
Vérifiez que la relation \(\rel\) définie sur \(S_n\) par \(\sigma\rel \rho\) si et seulement \(\sigma\) et \(\rho\) ont le même nombre de points fixes, est une relation d'équivalence. En déduire que
\[n!=\sum_{k=0}^n F_{n,k}.\]
Montrez que \( F_{n,k}=\binom{n}{k}!(n-k) \).
Montrez que la série entière \( \sum_{n\geqslant 0}\frac{!n}{n!}z^n \) a un rayon de convergence supérieur ou égal à 1.
On pose \( f(x)=\sum_{n=0}^{+\infty}\frac{!n}{n!}x^n \). Montrez que \( \exp(x)f(x)=\frac{1}{1-x} \) pour \( |x|<1 \).
En déduire que
\begin{equation}
!n=n!\sum_{k=0}^n\frac{(-1)^k}{k!}.
\end{equation}
Ces résultats seront utiles dans l'analyse de la complexité des algorithmes de tri en particulier.
Étude du taquin
Nous pouvons à présent étudier le problème du taquin et répondre à la question initiale. On numérote les cases du taquin dans l'ordre de lecture (cf. tableau à gauche ci-dessous), et on numérote également les 15 pièces du taquin de \(1\) à \(15\). Le numéro \(16\) est attribué à une pièce virtuelle, la pièce vide.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
1
2
3
4
5
6
7
8
9
10
11
12
13
15
14
À gauche : numérotation des cases du taquin. À droite : positions des pièces en configuration de Loyd.
En associant à chaque numéro de case du taquin le numéro de la pièce qui y est placée, la disposition des \(16\) pièces sur le taquin définit une permutation \(\sigma\in\Sn_{16}\). On l'appellera dans la suite la configuration du taquin.
La configuration du taquin proposée par Loyd est la permutation :
Elle ne contient qu'un seul cycle d'ordre 2, c'est la transposition \({\color{#88F}(14,15)}\).
Comment se traduit le déplacement d'une pièce \(k\) sur le taquin ? Compte tenu de la règle du jeu, on ne peut échanger la pièce \(k\) qu'avec la pièce vide numérotée \(16\). Autrement dit, un mouvement, quand il est possible, est nécessairement une transposition de la forme \((k,16)\) mais cette condition n'est pas suffisante. Pour qu'une transposition \((k,16)\) soit possible, il faut également que les pièces \(k\) et \(16\) soient adjacentes, c'est-à-dire qu'elles aient un côté commun.
Soit \(\sigma\) la permutation associée à une configuration du taquin. Nous dirons qu'une transposition \(\tau\) est compatible avec la configuration \(\sigma\) si et seulement si elle est de la forme \(\tau=(16,k)\) et que les pièces \(k\) et \(16\) sont adjacentes sur le taquin. Dans ce cas, \(\tau\sigma\) est une nouvelle configuration du taquin, on dira donc plus généralement qu'une permutation \(\pi\) est compatible avec la configuration \(\sigma\) si \(\pi\) est décomposable en un produit de \(n\) transpositions
\[\pi=\tau_{n}\,\tau_{n-1}\,\ldots\tau_2\,\tau_1.\]
telles que \(\forall i\in\ab{1}{n} \), \(\tau_i\) est compatible avec le produit
\[\tau_{i-1}\tau_{i-2}\ldots\tau_{1}\sigma.\]
Ce qui signifie ni plus ni moins qu'en partant de la configuration \(\sigma\), les transpositions \(\tau_1\) puis \(\tau_2\), etc. sont possibles dans cet ordre.
Pour résoudre une configuration \(\sigma\) du taquin, et celle de Loyd en particulier, il faut donc remettre toutes les pièces dans l'ordre, c'est-à-dire trouver une suite finie \(({\color{#FF8}\tau_i})_{i=1}^{n}\) de transpositions compatibles avec \(\sigma\) telle que son produit à gauche avec \(\sigma\) est la permutation identité, soit :
Isolons \(\sigma\) dans l'équation \((\ref{eq:sigmataquin})\). L'inverse d'un produit de bijections est le produit inverse des bijections réciproques (cf. exercice) et toute transposition \(\tau\) est une involution donc \(\tau^{-1}=\tau\), d'où
\begin{equation}
\label{eq:isolesigma}
\sigma={\color{#FF8}\tau_1\,\tau_{2}\,\ldots\,\tau_{n-1}\,\tau_n}.
\end{equation}
Nous dirons donc dans la suite qu'une configuration \(\sigma\) du taquin est résoluble s'il existe un produit de transpositions compatibles avec \(\sigma\) satisfaisant \((\ref{eq:isolesigma})\), insoluble sinon. Si une configuration est résoluble, les mouvements à réaliser effectivement sur le taquin sont les transpositions \(\tau_i\) dans l'ordre croissant des indices. Si un tel produit existe, sa signature doit bien sûr être égale à celle de \(\sigma\) :
Ces deux dernières égalités sont justifiées par le fait que la signature d'une transposition est égale à \(-1\) et que la signature d'un produit de permutations est égal au produit des signatures de ces permutations (cf. corollaire).
La signature de la configuration de Loyd \(\sigma=(14,15)\) est égale à \(-1\) puisqu'il s'agit d'une transposition. On déduit de \((\ref{eq:lastloyd})\) que l'on doit avoir \(-1=(-1)^n,\) autrement dit que le nombre \(n\) de transpositions dans le produit \(\color{#FF8}\pi\) doit être impair. Colorions les cases du taquin pour en faire un damier noir et blanc. La configuration initiale de Loyd est :
1
2
3
4
5
6
7
8
9
10
11
12
13
15
14
Configuration de Loyd sur un taquin en damier.
Une transposition de la forme \((16,k)\) fait passer alternativement la pièce vide d'une case noire à une case blanche. Pour que la pièce vide retrouve sa position initiale 16 sur le damier, le produit \({\color{#FF8}\pi}\) doit donc nécessairement contenir un nombre pair de transpositions, la configuration de Loyd est par conséquent insoluble. Nous venons de démontrer le théorème suivant :
Une configuration du taquin \(\sigma\) résoluble est paire.
Une condition nécessaire pour que taquin soit résoluble est que la configuration initiale définisse une permutation \(\sigma\) du groupe alterné \(\A_{15}\), si l'on suppose que la pièce vide est en position \(16\).
Cette condition est-elle suffisante ? Il faut garder à l'esprit que pour résoudre le taquin, il faut disposer d'un produit de transpositions compatible avec la permutation \(\sigma\) associée à la configuration initiale du taquin. Par exemple, seules les transpositions \((16,12)\) et \((16,15)\) sont compatibles avec la configuration de Loyd.
Nous allons montrer dans un premier temps que le groupe alterné \(\A_n\) est engendré par les \(3\)-cycles du type \((1,2,s)\) et dans un deuxième temps que tous les trois cycles de ce type sont décomposables en produit de transpositions compatibles avec l'identité.
Le groupe alterné \(\A_n\) est engendré par les \(3\)-cycles.
Montrons que le sous-groupe \(G\) de \(\Sn_n\) engendré par les \(3\)-cycles est contenu dans \(\A_n\). Soit \((x,y,z)\) un \(3\)-cycle, on peut le décomposer en le produit des deux transpositions \((x,y)(y,z)\). Sa signature est donc \(+1\), il appartient bien à \(\A_n\). Évidemment la composition de \(3\)-cycles conserve la parité, le groupe \(G\) est donc un sous-groupe de \(\A_n\). Réciproquement, montrons que tout élément de \(\A_n\) appartient à \(G.\) Soit \(\sigma\in\A_n\), elle admet une décomposition en un produit de \(2k\) transpositions \((\tau_i)_{i=1}^{2k}\) que l'on peut apparier comme suit :
\[
\sigma=(\tau_1\tau_2)\,(\tau_3\tau_4)\,\ldots\,(\tau_{2k-1}\tau_{2k}).
\]
Observons un seul appariement \(\tau_i\tau_{i+1}\), il y a quatre situations possibles :
et dans tous les cas, on peut l'écrire comme un produit de \(3\)-cycles.
Le groupe alterné \(\A_n\) est engendré par les \(3\)-cycles \((1,2,s)\) avec \(s\in\ab{3}{n}.\)
D'après le théorème précédent, il suffit de montrer que tout \(3\)-cycle \((i,j,k)\) peut se décomposer en produit de \(3\)-cycles de la forme \((1,2,r)\). Puisque \((i,j,k)=(j,k,i)=(k,i,j)\), on peut toujours supposer que \(i\) est le plus petit des trois. Il y quatre cas de figure :
\begin{align*}
(1,j,2) &= (1,2,j)^{-1},\\
(1,j,k) &= (1,2,k)\;(1,2,j)^{-1},\\
(2,j,k) &= (1,2,k)^{-1}\;(1,2,j),\\
(i,j,k) &= (1,2,k)\;(1,2,j)^{-1}\;(1,2,i)\;(1,2,k)^{-1}.
\end{align*}
Les \(3\)-cycles du type \((1,2,s)\) pour \(\A_{15}\) sont au nombre de \(13\) :
Et nous allons prouver que l'on peut réaliser n'importe lequel de ces \(3\)-cycles sur le taquin.
Soit \(k\in\N\) tel que \(k\geqslant 2\). On appelle circuit de longueur \(k\) toute séquence \((c_i)_{i=1}^k\) de cases distinctes du taquin telles que deux cases consécutives de cette suite sont toujours adjacentes et telle que \(\def\vide{{\color{#C22}16}}c_k\) est adjacente à \(c_1\). La suite des cases numéro 2, 3, 4, 8, 12, 16, 15, 14, 13, 9, 5, 6, matérialisée en rouge dans le taquin ci-dessous est un circuit de longueur \(12\) :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Un circuit de longueur 12 dans le taquin.
Démontrez qu'en coloriant les cases du taquin en damier, deux cases adjacentes d'un circuit sont de couleurs différentes. Démontrez que la longueur d'un circuit est toujours paire. Quelle est la longueur des circuits les plus courts ?
Dorénavant nous noterons \(\def\tua{{\color{#F44}\tau}}\tua_i:=(16,i)\), \(i\in\ab{1}{15}\) les 15 transpositions possibles sur le taquin. Soit \(\sigma\) la permutation associée à une configuration du taquin. Si on note \(p_i\) les pièces qui sont placées sur les cases \(c_i\) d'un circuit \((c_i)_{i=1}^{k}\) respectivement, on a donc
\[\forall i\in\ab{1}{k}\quad \sigma(c_i)=p_i.\]
Soit \(\sigma\) une configuration du taquin et \((c_i)_{i=1}^{k+1}\) un circuit de longueur \(k+1\) contenant respectivement les pièces \(p_i\) avec \(p_{k+1}=16\) la pièce vide. Alors le produit des \(k+1\) transpositions
\begin{equation}
\label{eq:permcirc}
\pi:=\tua_{p_1}\;\tua_{p_k}\;\tua_{p_{k-1}}\;\ldots\;\tua_{p_3}\;\tua_{p_2}\;\tua_{p_1}\;
\end{equation}
est compatible avec \(\sigma\). D'autre part, \(\pi\,\sigma\) réalise un décalage circulaire des éléments \(p_i\) dans les \(k\) premières cases du circuit \(c_i\).
Dans les grandes lignes : il faut généraliser l'exemple qui suit en partant d'un circuit quelconque et montrer que le contenu d'une case n'est modifié que par une seule transposition (ce qui explique la définition d'un circuit ici qui ne repasse jamais deux fois par la même case, le vocabulaire de la théorie des graphes parle de circuit hamiltonien) et que ce contenu après la transposition est bien le contenu de la case adjacente avant la transposition.
On considère une configuration \(\sigma\) du taquin et le circuit \(c:=(2,3,7,11,10,9,5,1)\) de longueur 8 sur lequel sont placées les pièces \(a,\) \(b,\) \(c,\) \(d,\) \(e,\) \(f,\) \(g\) et \(\vide\) respectivement. Calculons \(\pi\sigma\) avec le produit \(\pi\) défini par
\[\pi:=\tua_a\,\tua_g\,\tua_f\,\tua_e\,\tua_d\,\tua_c\,\tua_b\,\tua_a.\]
La pièce vide et la pièce adjacente \(k\) de la transposition \(\tau_k\) ont leur côté commun en pointillés :
\(a\)
\(b\)
\(g\)
\(c\)
\(f\)
\(e\)
\(d\)
\(\tua_{a}\)
\(a\)
\(b\)
\(g\)
\(c\)
\(f\)
\(e\)
\(d\)
\(\tua_{b}\)
\(a\)
\(b\)
\(g\)
\(c\)
\(f\)
\(e\)
\(d\)
\(\tua_{c}\)
\(a\)
\(b\)
\(c\)
\(g\)
\(f\)
\(e\)
\(d\)
\(\tua_{d}\)
\(a\)
\(b\)
\(c\)
\(g\)
\(d\)
\(f\)
\(e\)
\(\tua_{e}\)
\(a\)
\(b\)
\(c\)
\(g\)
\(d\)
\(f\)
\(e\)
\(\tua_{f}\)
\(a\)
\(b\)
\(c\)
\(g\)
\(d\)
\(f\)
\(e\)
\(\tua_{g}\)
\(a\)
\(b\)
\(c\)
\(d\)
\(g\)
\(f\)
\(e\)
\(\tua_{a}\)
\(b\)
\(c\)
\(a\)
\(d\)
\(g\)
\(f\)
\(e\)
Rotation des pièces autour d'un circuit sur le taquin.
On a montré que le produit \(\pi:=\tua_a\,\tua_g\,\tua_f\,\tua_e\,\tua_d\,\tua_c\,\tua_b\,\tua_a\) est compatible avec la permutation \(\sigma\) et en calculant \(\pi\,\sigma\), on a remplacé la séquence \(\color{#AAF}(a,b,c,d,e,f,g)\) par la séquence \(\color{#AAF}(b,c,d,e,f,g,a)\) sur ce circuit et il suffit d'itérer \(\pi\) pour faire tourner ces pièces autour du circuit en laissant toutes les autres fixes.
Dans le cas particulier où le circuit est un carré \(2\times 2\), on a le produit suivant (on ne représente plus les autres pièces qui sont fixes) :
\(a\)
\(c\)
\(b\)
\(\tua_{a}\)
\(a\)
\(c\)
\(b\)
\(\tua_{b}\)
\(a\)
\(b\)
\(c\)
\(\tua_{c}\)
\(a\)
\(b\)
\(c\)
\(\tua_{a}\)
\(b\)
\(a\)
\(c\)
Création d'un \(3\)-cycle sur le taquin.
Ce qui réalise une rotation des trois valeurs \(\color{#AAF}(a,b,c)\). Par exemple, en partant de la configuration identité \(\sigma:={\Id}\), on obtient le \(3\)-cycle \((11,12,15)\) à l'aide des quatre transpositions :
\[\tua_{15}\,\tua_{12}\,\tua_{11}\,\tua_{15}.\]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
1
2
3
4
5
6
7
8
9
10
12
15
13
14
11
Création du \(3\)-cycle \((11,12,15)\) sur le taquin.
Mais nous cherchons à construire les \(3\)-cycles particuliers de \((\ref{troiscycles})\) pour engendrer le groupe \(\A_{15}\). Le lemme suivant est évident mais important.
On peut déplacer la pièce vide sur n'importe quelle case \(i\in\ab{1}{16}\) du taquin et il faut au plus \(6\) transpositions \(\tua_{k}\) pour ce faire.
Quelle que soit la position initiale de la pièce vide sur le taquin, il y a au plus trois colonnes et trois lignes à parcourir pour atteindre la case \(i\).
Nous allons montrer comment obtenir le cycle \(\color{#AAF}(9,10,13)\) avec les techniques de transposition présentées. On note \(\sigma:=\tua_{14}\tua_{15}\) la permutation qui déplace la pièce vide à la case 14.
On fait alors tourner \(9,\) \(10\) et \(13\) autour du circuit grâce au produit \(\tua_{13}\,\tua_{10}\,\tua_{9}\,\tua_{13}\) et on ramène la pièce vide en case 16 :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
\(\sigma\)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
\(\tua_{13}\,\tua_{9}\,\tua_{10}\,\tua_{13}\)
1
2
3
4
5
6
7
8
10
13
11
12
9
14
15
\(\sigma^{-1}\)
1
2
3
4
5
6
7
8
10
13
11
12
9
14
15
Réalisation du \(3\)-cycle \((9,10,13)\) sur le taquin.
On a donc montré à l'aide d'une conjugaison que :
\begin{align*}
(9,10,13)&=\sigma^{-1}\,\tua_{13}\,\tua_{9}\,\tua_{10}\,\tua_{13}\,\sigma,\\
&=(\tua_{15}\,\tua_{14})\,\tua_{13}\,\tua_{9}\,\tua_{10}\,\tua_{13}\,(\tua_{14}\,\tua_{15}).
\end{align*}
Le programme que vous avez pu utiliser en début de chapitre et qui résout le problème du taquin dans le cas où la permutation \(\sigma\in\A_{16}\) applique exactement la stratégie que nous venons de déployer. Résumons :
On décompose \(\sigma\) en produit de cycles (cf. théorème),
On décompose chaque cycle du produit en produit de transpositions (cf. théorème),
On construit un produit de \(3\)-cycles en appariant ces transpositions (cf. théorème),
On décompose ces \(3\)-cycles en \(3\)-cycles du type \((1,2,s)\) (cf. proposition),
On calcule l'inverse de ce produit,
Pour chaque élément du produit inverse, on exécute la séquence de déplacements appropriés sur le taquin.
Vous pouvez voir ces étapes en faisant apparaître la console javascript dans votre navigateur (sous Chromium, il suffit de cliquer sur \(\boldsymbol\vdots\) en haut à droite, puis de sélectionner "Plus d'outils" et "Outils de développement").
Vous avez pu constater que le nombre de mouvements pour remettre les pièces dans l'ordre est conséquent, quel est le nombre minimum de déplacements nécessaires pour résoudre une configuration ? Peut-on simplifier les produits de \(3\)-cycles ?
Construisez le \(3\)-cycle \((1,2,3)\) à l'aide de transpositions compatibles. Indication : considérez le circuit formé par les \(12\) cases en bordure du taquin en configuration identité et faites tourner les \(11\) pièces autres que la pièce vide d'une position dans le sens anti-horaire. Déplacez la pièce vide sur la case numéro \(6\) et faites tourner les pièces \((1,2,3)\) puis ramenez la pièce vide en position \(16\).
Vérifiez que \((1,2,4)\) est le conjugué de \((1,2,3)\) par \((3,4,8,12,15,11,7)\).
En vous inspirant de cet exemple, construisez les \(3\)-cycles suivants :
\begin{align*}
&(1,2,5),&\quad&(6,11,7),&\quad&(3,6,7),\\
&(5,9,6),&\quad&(6,10,7),&\quad&(3,8,4),\\
&(11,15,12),&\quad&(10,14,11),&\quad&(9,13,10).\\
\end{align*}
Calculer le conjugué de \((1,6,2)\) avec \((5,9,6)\). Avec d'autres conjugaisons, trouvez tous les \(3\)-cycles manquants.
Travaux pratiques
Nano tutoriel Python-UNIX à imprimer/lire/conserver.
En séance
Dans la suite, une permutation \(\sigma\in{S}_n\) est considérée comme la séquence des images \(\sigma(i)\) pour \(i\in\ab{1}{n}\) et donc codée en Python par la liste \([\sigma(1),\sigma(2),\ldots,\sigma(n)]\). Comme les indices des types énumérés commencent à 0 et pas à 1 en Python, on décrémente la valeur des images. Autrement dit la permutation
\begin{pmatrix}
1&2&3&4\\
\color{#FF8}3&\color{#FF8}2&\color{#FF8}1&\color{#FF8}4
\end{pmatrix}
est codée par la liste [2,1,0,3]. La saisie d'une permutation et son affichage resteront en revanche conformes aux notations mathématiques usuelles. Ainsi, pour lire et afficher une permutation, un cycle ou une orbite, vous utiliserez les fonctions suivantes :
# Lecture d'une permutation
def Lire(texte = "s = "):
chaine = input(texte)
return [int(x)-1 for x in chaine.split()]
# Formatage en chaîne
def Formater(s):
sortie = [i + 1 for i in s]
if isinstance(s,tuple):
return str(tuple(sortie))
elif isinstance(s,set):
return str(set(sortie))
else:
return str(sortie)
La fonction Lire renvoie la liste des valeurs entières décrémentées d'une unité à partir de la chaîne de caractère lue au clavier. La fonction Formater convertit une permutation, un cycle ou une orbite en chaîne de caractères après avoir incrémenté chaque valeur de la structure d'une unité.
Pour éviter les problèmes de conformité d'indexation des listes Python avec les permutations, vous pourriez également coder une permutation de \(S_n\) par une liste de longueur \(n+1\) et n'utiliser que les positions de \(1\) à \(n\).
Écrivez une fonction EstPermutation(s) qui décide (c'est-à-dire qui renvoie True ou False) si la liste s code une permutation ou non.
Indication : utilisez une liste B de booléens de même longueur que s tous initialisés à False qui permettra de marquer les valeurs rencontrées en parcourant s. (Vous pourriez également convertir s en Set, l'ensemble ainsi obtenu est égal à \(\{0,1,\ldots,|s|-1\}\) si et seulement si s est une bijection.)
Écrivez une fonction Inverser(s) qui renvoie la liste codant la permutation inverse \(s^{-1}\) de la permutation codée par la liste \(s\).
Écrivez une fonction Composer(t,s) qui renvoie la liste codant la composition \(t\circ s\) des permutations codées par les listes \(t\) et \(s\). Vérifiez votre fonction en composant une permutation avec son inverse calculée à l'aide de la fonction précédente, vous devez retrouver la permutation identité.
Écrivez une fonction Orbite(k,s) qui renvoie l'orbite de \(k\) sous forme de setPython pour la permutation codée par la liste \(s\).
Écrivez une fonction Cycles(s) qui décompose une permutation s en produit de cycles à supports disjoints. Cette décomposition sera représentée par une liste de tuples codant les cycles.
Indication : utilisez une liste B de \(n\) booléens initialisés à True telle que \(B[i]\) est vrai si et seulement si l'orbite de \(i\) n'a pas encore été calculée.
Écrivez une fonction Transpositions(s) qui décompose une permutation s en produit de transpositions, et qui renvoie donc une liste de couples.
Écrivez une fonction Signature(s) qui calcule la signature de la permutation s passée en paramètre.
Indications : vous pouvez calculer la signature avec la formule du cours. On rappelle que le nombre d'orbites n'est pas nécessairement le nombre de cycles, aucun point fixe d'une permutation n'est un cycle, il constitue pourtant une orbite de taille \(1\). Vous pouvez également utiliser au préalable la décomposition en produit de cycles à supports disjoints puis décomposer chaque \(p\)-cycle en produit de \(p-1\) transpositions dont la signature est donc \((-1)^{p-1}\).
Compléments hors séance
Après avoir étudié le chapitre sur l'arithmétique, démontrez que le plus petit commun multiple des deux entiers naturels \(a\) et \(b\) (noté \([a,b]\) ou \(a\vee b\)) est égal au quotient
\[[a,b]=\frac{a\, b}{(a,b)}\]
où \((a,b)\) désigne le pgcd de \(a\) et \(b\). Soit \(n\) un entier \(n\geqslant 3\). Démontrez par récurrence que pour une séquence d'entiers naturels \(a_1,a_2,\ldots, a_n\) on a
Écrivez une fonction PGCD(a,b) qui calcule le pgcd des deux entiers naturels \(a\) et \(b\).
Utilisez la propriété \((\ref{eq:ppcm})\) pour écrire une fonction (itérative) PPCM(liste) qui calcule le ppcm des entiers contenus dans la liste passée en paramètre.
Utilisez les résultats ci-dessus pour écrire une fonction Ordre(s) qui calcule l'ordre de la permutation passée en paramètre.
Écrivez une fonction Type(s) qui calcule le type de la permutation passée en paramètre.
Écrivez une fonction Conjuguer(s,r) qui calcule la conjuguée de la permutation \(s\) par \(r\).