| matière \(\Downarrow\) première | |
 | \(\Rightarrow\) produit fini |
Nous utilisons des algorithmes en permanence, non seulement en mathématiques et en informatique, ou plus généralement dans le domaine des sciences, mais tout simplement dans la vie quotidienne pour réaliser une quantité de tâches incroyablement variées. Nous nous servons d'algorithmes pour nous habiller, préparer un café, calculer le montant de nos impôts, vérifier l'état d'un véhicule, etc. La définition suivante est une synthèse des multiples définitions du mot algorithme glanées dans les dictionnaires.
Notons immédiatement qu'il n'est nullement fait mention d'un ordinateur dans cette définition. À juste titre puisqu'on a pu retrouver des algorithmes datant de plusieurs milliers d'années. Les babyloniens développaient déjà des algorithmes de factorisation ou d'extraction de racines carrées 1600 ans avant JC.
L'archétype de l'algorithme est la recette de la tarte aux pommes. Elle décrit les opérations élémentaires à réaliser pour l'obtention de la tarte (la sortie) à partir des ingrédients (l'entrée) :
Les 10 opérations successives de la préparation composent l'algorithme et décrivent comment procéder pour résoudre ce problème. Elles font apparaître trois structures syntaxiques caractéristiques des algorithmes :
Le pâtissier professionnel s'intéressera sans aucun doute à la complexité des recettes, et préférera une recette qui demande 20 minutes de préparation à une autre qui en demande \(45\), pour un résultat identique s'entend.
La recette proposée ici est suffisamment détaillée pour un être humain, mais elle souffre de quelques limitations. Elle ne précise pas comment préparer une compote de pommes (ce qui justifierait l'écriture d'un algorithme spécifique, tout comme la préparation de la pâte si elle n'était pas toute faite), ni comment allumer et régler le four selon sa nature (à bois, électrique, au gaz ?). Elle s'adresse manifestement à une personne adulte qui a des connaissances préalables en cuisine. Si nous devions décrire tout ceci à un enfant, il faudrait sans doute décomposer ces opérations en tâches plus simples et certaines d'entre elles en d'autres plus simples encore.
Cette approche dite en analyse descendante définit implicitement un parcours arborescent et constitue une technique fondamentale de conception des algorithmes. Comme nous l'avons fait remarquer, la finesse de la décomposition de certaines tâches est dépendante du public auquel s'adresse la recette. Il en ira de même pour l'implantation d'un algorithme selon le modèle de calcul utilisé. L'effort à fournir pour écrire un programme en langage Python n'est pas le même qu'avec un langage d'assemblage.
L'objectif principal de l'algorithmique est de concevoir des méthodes efficaces pour automatiser la résolution d'un problème. La conception d'un algorithme n'est donc qu'une partie de cet objectif, il faut également s'assurer qu'il est efficace, ce qui se traduit dans ce contexte par une économie des ressources en temps et en espace. Les deux aspects sont abordés à la fois dans la phase de conception et la phase d'analyse qui ne sont pas indépendantes, elles constituent le fil rouge de ce cours.
Même si notre première définition résume de manière tout à fait satisfaisante le concept, elle est inutilisable en l'état pour en faire le socle d'une théorie. Le problème est similaire à celui qu'a rencontré le mathématicien G. Cantor quand il a voulu définir formellement le concept d'ensemble et édicter des règles pour les construire. Sa définition et le principe d'abstraction (tout prédicat engendre un ensemble constitué des éléments qui le satisfont) aboutissaient immanquablement à des paradoxes, et il a fallu attendre les travaux de E. Zermelo et A. A. Fraenkel sur la théorie des ensembles (souvent résumée en théorie zf) pour comprendre qu'il était nécessaire d'établir des règles strictes pour construire de nouveaux ensembles à partir du germe que constitue l'ensemble vide \(\varnothing\). Les travaux ultérieurs du mathématicien K. Gödel ont alors permis de cerner les limites de toute théorie mathématique.
Les recherches effectuées par les mathématiciens pour formaliser la notion de calcul ou d'algorithme, et ceci avant même que le mot ordinateur ne soit forgé, ont été aussi prolifiques et précieuses que celles qui ont abouti à la théorie zf utilisée de nos jours. Il existe d'ailleurs de multiples intersections entre ces deux théories. De nombreux modèles mathématiques ont été proposés pour cadrer au plus juste ce concept et on sait aujourd'hui que tous sont équivalents. Autrement dit, ce que l'on est capable de résoudre comme problèmes, ou ce que l'on est en mesure de calculer, ne dépend pas du modèle algorithmique choisi — du moment que ce modèle respecte les propriétés universellement reconnues comme caractéristiques d'un algorithme — en particulier celles que nous avons mises en évidence dans l'exemple de la recette de la tarte aux pommes. C'est ce que conjecturait le logicien américain Alonzo Church, inventeur du \(\lambda\)-calcul, avant même que l'on ne prouve formellement l'équivalence des modèles abstraits en lice. Le chapitre suivant est consacré à l'étude d'un modèle formel structurellement proche des ordinateurs, la machine ram, c'est à cette occasion que nous pourront définir formellement un algorithme.
La structuration et l'expression d'un calcul est intimement liée au modèle considéré, elle est souvent qualifiée de programme. Dans ce contexte formel, algorithme et programme sont donc synonymes. Si la façon d'exprimer un algorithme est très variable, son mode opératoire reste largement indépendant du modèle mathématique considéré. Un algorithme traite des données initiales constituant son entrée en construisant de nouvelles quantités dont certaines, une fois le calcul achevé, sont interprétées comme un résultat, sa sortie.
Une deuxième approche imagée est de considérer un algorithme comme une machine physique qui traite une matière première (les ingrédients de la tarte aux pommes) pour la transformer en produit fini (la tarte aux pommes). La description du fonctionnement rudimentaire d'un hachoir à viande devrait suffir à comprendre l'hypotypose.
| matière \(\Downarrow\) première | |
| \(\Rightarrow\) produit fini |
La viande en morceaux est fournie en entrée dans l'entonnoir et la rotation de la manivelle l'entraîne vers le couteau à l'aide d'une vis sans fin. La machine renvoie en sortie la viande hachée.
L'articulation entre un algorithme et ses entrées/sorties est parfaitement modélisée par une fonction. En effet, l'écriture schématique \[x\stackrel{f}{\longmapsto}y\] d'une fonction mathématique \(f\) résume parfaitement la dynamique d'un algorithme. L'idée suggérée par cette écriture en la lisant de gauche à droite est qu'un objet \(x\) est transformé en un objet \(y\) par l'entremise de la fonction \(f\). Dans certains cas, cette transformation peut être décrite à l'aide d'une expression algébrique, comme par exemple \(x\mapsto x^2 -3x + 1,\) ce qui cadre bien avec l'idée naïve que l'on se fait d'un calcul. Une autre écriture classique d'une fonction précise la nature des objets \(x\) et \(y\) en spécifiant l'ensemble de départ et l'ensemble d'arrivée : \begin{equation} %\bbox[border:1px solid white; padding:12px]{ f:\begin{matrix} X\rightarrow Y\\ {\color{#F84}x}\mapsto \color{#BBF}y \end{matrix}%} \end{equation}
On peut résumer cette articulation par un schéma qui s'en inspire fortement : \(\color{yellow}x\) est assimilé à l'entrée de l'algorithme, \(\color{#BBF}y\) à la sortie, les ensembles de départ et d'arrivée précisent le type des données, et la fonction \(f\) joue le rôle de l'algorithme, ici \({\color{#FA4}x}\mapsto {\color{#BBF}x^2-3x+1}\) :
Il ne faut pas déduire de cette analogie que toute fonction mathématique est un algorithme. Si tout algorithme définit implicitement une fonction, la réciproque est fausse en général. L'objet de la théorie de la calculabilité, généralement étudiée en master, est précisément l'étude de cette réciproque.
Nous allons affiner ce premier schéma. L'entrée comme la sortie sont modélisées respectivement par deux mots*L'ensemble des mots sur un alphabet \(A\) est noté \(A^*\) définis sur un alphabet d'entrée \(\Sigma\) et un alphabet de sortie \(\Gamma\). L'entrée du programme est obtenue via un schéma d'encodage qui désigne de manière un peu pompeuse une façon de traduire les données réelles et bien concrètes de notre monde en objets abstraits qui pourront être manipulés par des outils d'une théorie mathématique. Par exemple un triplet \(({\color{#F00}R},{\color{#0F0}V},{\color{#00F}B})\in\ab{0}{255}^3\) de trois octets peut représenter la couleur d'un pixel sur un écran. C'est ce que j'ai fait ici même dans le codage html de ce document avec les valeurs hexadécimales \(\color{#F00}\verb+F00+,\) \(\color{#0F0}\verb+0F0+\) et \(\color{#00F}\verb+00F+\) pour distinguer ces trois couleurs respectivement dans le texte. Symétriquement, la sortie du programme est elle même interprétée à l'aide d'un schéma de décodage.
La figure ci-dessous résume tout ceci :
| Langage naturel | abstraction | Modèle de calcul | abstraction | Langage naturel | ||||
| instance | \(\xrightarrow[\text{d'encodage}]{\text{schéma}}\) | \(x\in\Sigma^*\) | \(\xrightarrow[]{\phantom{\text{entrée}}}\) | algorithme programme | \(\xrightarrow[]{\phantom{\text{sortie}}}\) | \(y\in\Gamma^*\) | \(\xrightarrow[\text{de décodage}]{\text{schéma}}\) | résultat |
| Question | entrée | Calcul | sortie | Réponse | ||||
Nous n'avons par encore spécifié la manière dont les informations doivent être manipulées par un algorithme. Tous les modèles abstraits intègrent l'aspect séquentiel des étapes à franchir pour résoudre le problème ainsi que la définition d'un ensemble fini de règles strictes pour assurer cette progression. Le déterminisme de l'algorithme est également fondamental, son comportement doit être parfaitement défini en toute circonstance et reproductible. En ce sens, le paradigme de programmation qui est suggéré par cette approche est la programmation impérative qui décrit comment résoudre un problème. La programmation déclarative est un autre paradigme de programmation dans lequel on fournit une description du problème à travers des structures, fonctions, relations, ou des contraintes.
À titre d'illustration, étudions un premier problème. On veut déterminer si un mot est un palindrome, c'est-à-dire si ce mot s'écrit exactement de la même façon à l'endroit et à l'envers comme le mot radar par exemple. Le problème se généralise souvent à des phrases entières en ne tenant compte que des lettres et en omettant les espaces et autres symboles.
La résolution de ce problème ne pose pas de grandes difficultés, il suffit de comparer les lettres du mot avec celles de ce même mot écrit à l'envers. Trouver une méthode générale pour résoudre un problème est une première victoire, mais il reste quelques étapes à franchir avant d'être en mesure d'en extraire un programme informatique, qui plus est efficace. En effet, la méthode décrite dans notre phrase est imprécise, incomplète et ambiguë. Elle est suffisante pour un être humain car il est capable de
L'analyse du problème permet de fixer un cadre théorique adéquat pour sa résolution et ainsi de choisir les modèles de données les mieux adaptés pour y parvenir. On parle parfois d'algèbre de conception. Ce sont les structures algébriques utilisées en mathématiques qui sont les outils privilégiés pour représenter les objets à manipuler. Nous verrons que les modèles de données informatiques sont majoritairement des structures algébriques bien connues ou des déclinaisons plus ou moins fidèles de ces structures. Ces modèles de données sont à leur tour déclinés en structures de données dans les langages de programmation.
Dans le cadre de la résolution du problème du palindrome, la théorie des langages, tout au moins une part homéopathique, s'avère adaptée à sa description formelle via un ensemble fini \(A=\{a_0,a_1,\ldots,a_{q-1}\}\) appelé alphabet et constitué des lettres ou symboles \(a_i\). Toute séquence \(u\) de \(n\) lettres de \(A\) est appelée mot de longueur \(n,\) longueur que l'on désigne par \(|u|\) ou \(\#u\). On note \(A^n\) l'ensemble (fini) de tous les mots de longueur \(n\) et \(A^*\) l'ensemble (infini) de tous les mots possibles. Par analogie avec les langues naturelles et par économie, on écrit les termes d'une séquence sans les séparer par des virgules. Le miroir d'un mot \(u=u_1u_2\ldots u_n\) est le mot \(u_nu_{n-1}\ldots u_1\). Un langage est un sous-ensemble de \(A^*\). Par exemple, la langue française est un langage, c'est un sous-ensemble fini de tous les mots que l'on peut constituer avec les symboles de l'alphabet latin \(A=\{a,b,c,\ldots,z\}\). Le mot algorithme est un mot de la langue française contrairement au mot ahhhleborythme.
Un mot de \(n\) lettres de la langue française est donc modélisé par un mot (abstrait) \(u=u_1u_2\ldots u_n\) de longueur \(n\). Ce passage du réel au formel et le choix que nous avons fait pour représenter un mot de la langue française constitue précisément un schéma d'encodage. Dans ce cas précis, ce passage est simple et ne pose aucune difficulté. À présent, savoir si un mot \(u=u_1u_2\ldots u_n\) est ou non un palindrome se traduit mathématiquement par la valeur de vérité de la proposition \begin{equation}\label{eq:egseq} %\stackrel{?}{=} ou \overset{?}{=} u_1u_2\ldots u_n \stackrel{?}{=} u_nu_{n-1}\ldots u_1 \end{equation}
Ce lemme permet de valider formellement cette approche et l'assertion (\ref{eq:egseq2}) suggère un procédé itératif pour s'assurer que l'égalité (\ref{eq:egseq}) est satisfaite ou non : en notant \(v\) le miroir de \(u,\) il suffit de vérifier que l'égalité \(u_i=v_i\) est satisfaite pour tous les indices \(i\) variant de \(1\) à \(n\). Si à une étape \(i\) donnée \(u_i\not=v_i,\) on peut affirmer que \(u\) n'est pas un palindrome sans avoir à poursuivre les vérifications. En revanche si toutes ces égalités ont été vérifiées, on peut affirmer que \(u\) est un palindrome.
On peut résumer tout ceci par un algorithme qui procède en deux phases, la première construit le mot miroir \(v\) (lignes #1 à #2b), la seconde compare \(u\) et \(v\) terme à terme (lignes #3 à #5) :
Il est manifeste que le nombre d'instructions exécutées pour décider si un mot \(u\) est un palindrome ou non, dépend de la longueur \(n\) du mot \(u\) sans même définir précisément ce que l'on entend par instruction. Mais ce nombre d'instructions dépend également de la nature du mot, en effet, comme nous l'avons déjà remarqué, il est inutile de continuer les comparaisons dès que l'on a trouvé deux symboles \(u_i\) et \(v_i\) distincts, ce qui peut survenir bien avant d'atteindre la fin du mot. Nous allons dans ce chapitre et en première approximation considérer que chaque ligne de cet algorithme définit une instruction, notion qui sera formalisée au chapitre suivant.
Les instructions #1, 3 et 5 ne sont exécutées qu'une seule fois. Les instructions #2a et 2b le sont \(n\) fois chacune. L'instruction #2 est exécutée \(n+1\) fois. Pour un mot \(u\) donné, notons \(p(u)\in[1,n+1]\) la plus petite valeur de \(i\) telle que la condition \(i\leq n\) et \(u_i=v_i\) n'est plus satisfaite, soit : \begin{equation*} p(u) := \min\{i\in[1,n+1]\ \ |\ \ (i>n)\vee(u_i\not=v_i)\}. \end{equation*}
Alors l'instruction #4 est exécutée \(p(u)\) fois et l'instruction #4a exactement \(p(u)-1\) fois. Finalement en sommant, on en dénombre \begin{equation} 3+2n+(n+1)+p(u)+(p(u)-1)=3n+2p(u)+3. \end{equation}
Le nombre d'instructions exécutées est minimal quand les deux premiers symboles sont distincts, i.e. quand \(u_1\not=v_1,\) soit \(3n+5\) instructions puisque \(p(u)=1\). Le maximum est atteint quand \(u=v,\) soit \(5n+5\) instructions si \(p(u)=n+1\).
Le lecteur avisé aura deviné qu'il est possible d'être plus économe pour décider si un mot \(u\) est un palindrome ou non avant même que l'exercice précédent ne suggère de modifier la fin de la boucle. On peut faire encore mieux en évitant tout simplement de construire préalablement le mot \(v\) et en comparant directement les symboles de \(u\) entre eux :
Il y a cette fois \(2\lfloor\frac{n}{2}\rfloor +3\) instructions qui sont exécutées dans le pire des cas et \(3\) dans le meilleur des cas, ce qui est bien meilleur qu'avec notre premier algorithme.
Pour simplifier le problème et permettre une analyse plus générale, on suppose que l'on dispose d'un alphabet \(A\) de cardinal \(q,\) que l'espace des instances de l'algorithme est le langage \(A^n\) et que toutes les instances sont équiprobables. Notons que cette hypothèse d'équiprobabilité est très éloignée de la réalité, un mot de longueur 3 de la langue française qui commence par \(qu\) est certainement suivi par l'une des voyelles \(e,i\) ou \(o\).
L'expérience aléatoire consiste donc à tirer un mot \(u\) de \(A^n\) au hasard, l'espace d'échantillonnage \(\Omega\) est alors le langage \(A^n\). On note \(p(u)\) le nombre de fois où l'expression \((\ref{eq:testpal})\) a été évaluée lors de l'exécution de l'algorithme pour l'instance \(u\). Pour \(k\in[1,\lfloor\frac{n}{2}\rfloor+1],\) on définit l'évènement \[\Omega_k:=\{u\in \Omega\ |\ p(u)=k\}.\]
(1) Justifiez que \begin{equation} \label{eq:probaprod} \prob(\Omega_k) = \begin{cases} \prob(u_{k}\not=v_{k})\times\displaystyle\prod_{i=1}^{k-1} \prob(u_i=v_i)&\text{si}\ k\in[1,\lfloor\frac{n}{2}\rfloor],\\ \displaystyle\prod_{i=1}^{\left\lfloor\frac{n}{2}\right\rfloor} \prob(u_i=v_i)&\text{si}\ k=\lfloor\frac{n}{2}\rfloor+1. \end{cases} \tag{$\Pi$} \end{equation} (2) Montrez que \begin{equation*} \forall i\in[1,\lfloor\frac{n}{2}\rfloor],\quad \prob(u_i=v_i)=\frac{1}{q}\ \text{et}\ \prob(u_i\not=v_i)=1-\frac{1}{q} \end{equation*} (3) Montrez que les évènements \(\Omega_k\) sont incompatibles.
(4) Montrez qu'aucun des ensembles \(\Omega_k\) n'est vide.
(5) Montrez que la réunion des ensembles \(\Omega_k\) est l'ensemble \(\Omega:=A^n\).
(6) En déduire que le nombre moyen de tests pour traiter un mot de longueur \(n\) est égal à \begin{equation} \label{eq:sum} \left(\frac{1}{q}\right)^{\lfloor\frac{n}{2}\rfloor}+ (q-1){\color{orange}\underbrace{\sum_{k=1}^{\lfloor\frac{n}{2}\rfloor}k\left(\frac{1}{q}\right)^{k}}_{S}}. \end{equation}
(7) Calculez l'expression \((\ref{eq:sum})\). Indication : cf. chapitre de combinatoire pour calculer la somme \(\color{orange}S\).
(8) Quelle est le nombre moyen de tests effectués, asymptotiquement sur la longueur des mots ?
Cette étude nous a permis de mettre en évidence les 4 grandes étapes à franchir pour passer d'un problème à sa résolution à l'aide d'un algorithme :
L'écriture d'un programme informatique dans un langage particulier pour la résolution effective d'un problème constitue une 5ème étape qui recèle elle aussi des difficultés, de nature et de magnitude différentes selon le langage utilisé. Il faut en premier lieu trouver les structures correspondant aux modèles utilisés ou les construire quand elles n'existent pas. Par exemple la gestion des chaînes de caractères et des listes en Python est simple et agréable alors qu'elle est particulièrement délicate et fastidieuse en langage C (avec d'autres atouts en contrepartie).
Adaptons les deux algorithmes de décision sur le palindrome présentés à la section précédente en langage Python et observons à travers cet exemple quelques écueils inhérents à la programmation :
def Est-Palindrome1(u):
n = len(u)
v = ""
i = 0
while (i < n):
v = u[i] + v
i = i + 1
i = 0
while (i < n) and (u[i] == v[i]):
i = i + 1
return (i >= n)
def Est-Palindrome2(u):
n = len(u)
i = 0
while (i < n//2) and (u[i] == u[n - (i + 1)]):
i = i + 1
return (i >= n // 2)
Mentionnons l'extraordinaire maladresse commise lors de la conception du langage C, dont a hérité le Python, à savoir le codage de l'affectation par le symbole mathématique \(=\) dont la signification universelle est l'égalité. Ce choix imposait un codage différent pour l'égalité logique, d'où le bégaiement \(==\).
Dans notre pseudo-langage algorithmique l'affectation sera codée par la flèche gauche \(\leftarrow\) largement répandue également.
Revenons à notre problème. La première difficulté est que la structure de chaîne de caractères commence son indexation à 0 et non à 1 comme nous l'avons fait dans l'algorithme. L'impact n'est pas anodin, le résultat de l'exercice 1 qui nous a permis de prouver que l'algorithme était juste, suppose que l'indice \(i\) appartient à l'intervalle \(\ab{1}{n}\) et non à l'intervalle \(\ab{0}{n-1}\). L'adaptation, sans analyse formelle préalable, peut s'avérer périlleuse et occasionne une perte de temps considérable en développement. Ici les inégalités larges des tests initiaux ont été remplacées par des inégalités strictes.
Un danger est tapi dans la condition (i < n) and (u[i] == v[i]) de la boucle while de la fonction Est-Palindrome1. L'expression utilisée pour cette condition est parfaitement naturelle puisqu'elle code ce que nous ferions à la main, à savoir : tant que l'on n'a pas atteint la fin du mot et que les lettres sont identiques, on avance. Sans nécessairement en avoir conscience, nous évaluons des conjonctions et des disjonctions de manière paresseuse♯Shortcut en anglais.. En lisant de gauche à droite, nous cessons d'évaluer les opérandes des formes conjonctives ou disjonctives dès que la valeur logique de l'expression est déterminée :
Il n'est pas certain qu'un langage de programmation évalue une expression de manière paresseuse comme le ferait un être humain, et ceci peut poser quelques problèmes. Dans l'évaluation d'une expression, une première phase consiste à faire une analyse lexicale et à segmenter la chaîne de caractères en unités lexicales (jetons), constantes, opérateurs, identificateurs, etc.*Ces notions d'analyse lexicale et syntaxique seront étudiées en détail dans le cours de théorie des langages et compilation en 3ème année. Un programme qui construit l'arbre syntaxique d'un expression arithmétique est disponible au chapitre évaluation d'une expression avec une pile
Les unités lexicales sont ensuite rangées dans un arbre syntaxique :
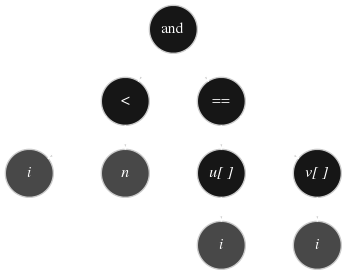
Chaque opérateur est rangé dans un nœud de cet arbre binaire dont les fils sont ses opérandes (le nombre de fils correspond à l'arité de l'opérateur). Ici nous sommes en présence d'opérateurs binaires (\( < \) ou \( == \) par exemple) et unaire (\([\ ]\)). Le procédé est récursif, si un opérande est lui même une expression, son nœud devient la racine du sous-arbre qui la représente etc. Cet arbre est ensuite évalué récursivement, chaque nœud est alors remplacé par le résultat de l'opération.
En soi, l'expression logique \((i < n)\wedge (u_i=v_i)\) n'induit aucune dynamique, et on pourrait permuter les deux opérandes de la conjonction puisque ce connecteur est commutatif, soit \((u_i = v_i) \wedge (i < n),\) sans que cela change quoi que ce soit à sa valeur logique.
A priori, rien n'indique comment l'arbre syntaxique va être évalué, il est même envisageable qu'il soit évalué dans son intégralité, ce qui invaliderait l'algorithme puisqu'une fois que l'indice \(i\) atteint la valeur \(n,\) la quantité \(u[i]\) n'est plus définie. Fort heureusement, les compilateurs et interprètes modernes évaluent les expressions de manière paresseuse, mais il faut s'en assurer et il est parfois préférable d'écrire des programmes robustes. À cette fin, on peut réécrire la fonction EstPalindrome1 de la manière suivante :
def Est-Palindrome-Bis(u):
n = len(u)
v = ""
i = 0
while (i < n):
v = u[i] + v
i = i + 1
i = 0
OnContinue = True;
while (i < n) and OnContinue:
OnContinue = (u|i] == v[i])
i = i + 1
return (i >= n)
def Est-Palindrome-Ter(u):
return u == u[::-1]
Cette écriture, aussi séduisante soit-elle pour le développeur pressé, a pour défaut majeur de cacher le nombre d'opérations exécutées par l'interprète Python pour évaluer l'expression et par conséquent laisse accroire au programmeur débutant que ces questions ne sont pas essentielles. Nous y reviendrons dans le chapitre consacré à la complexité.