Tous les algorithmes de tri que nous avons étudiés jusqu'ici s'appuient sur la comparaison des valeurs de la liste/tableau entre elles pour les trier, on parle donc de tri comparatif. Nous avons vu que la complexité des tris dits empiriques est quadratique alors que le tri par tas est linéarithmique \(\Theta(n\,\log n)\). La question naturelle qui émerge des études de complexité que nous avons menées est : Quelle est la complexité minimale dans le pire des cas d'un tri comparatif ? Nous allons montrer que cette complexité ne peut être meilleure que \(\Omega(n\,\log n)\).
Pour pouvoir comparer les éléments d'une liste, il faut que ses termes soient comparables au sens où ils appartiennent à un ensemble \(E\) ordonné. Nous supposerons donc que l'ensemble \(E\) est muni d'une relation d'ordre notée \(\preccurlyeq\) et qu'il s'agit plus précisément d'une relation d'ordre total.
Le lemme et les exercices qui suivent montrent d'une part que l'on ne perd pas en généralité en ne considérant que des listes à valeurs entières et d'autre part que l'on peut également se limiter à des listes qui sont des permutations. L'idée est que du point de vue de l'ordre, on peut remplacer dans une liste \(L\) de \(n\) éléments d'un ensemble totalement ordonné \((E,\preccurlyeq)\) chacune des \(n\) valeurs par sa position dans la liste triée de \(L\). On remplace donc l'ordre total \(\preccurlyeq\) qui équipe \(E\) par l'ordre naturel \(\leq\) qui équipe \(\mathbb N\) sans perturber les comparaisons entre éléments. Par exemple, toute comparaison entre deux éléments de la liste de nombres réels \([\pi,\,2.5,\,e,\,1.3]\) pour l'ordre lexicographique a la même valeur de vérité que la comparaison correspondante dans la liste d'entiers naturels \([4,\,2,\,3,\,1]\) pour l'ordre naturel.
Soit \(L\) une liste de taille \(n\) à valeurs dans un ensemble totalement ordonné \((E,\preccurlyeq)\). Alors, il existe une permutation \(\sigma\in{\frak S}_n\) telle que
\begin{equation}\label{eq:permimp}
\forall (i,j)\in \ab{1}{n}^2\quad (\sigma(i) \leqslant \sigma(j)) \Rightarrow (L[i] \preccurlyeq L[j]).
\end{equation}
Si la liste ne contient que des valeurs distinctes alors il s'agit d'une équivalence dans \((\ref{eq:permimp})\).
Démontrons la première partie, l'autre est laissée en exercice. Puisque l'ordre est total, on peut ordonner les \(n\) termes de la liste \(L\) dans l'ordre croissant, autrement dit il existe (au moins) une permutation \(s\in{\frak S}_n\) telle que
\begin{equation}\label{eq:omega}
\forall i\in[1,n-1],\quad L[s(i)]\preccurlyeq L[s(i+1)].
\end{equation}
Par induction, on en déduit que
\begin{equation}\label{eq:omega2}
\forall (i,j)\in\ab{1}{n}^2,\quad i\leqslant j\Rightarrow L[s(i)]\preccurlyeq L[s(j)].
\end{equation}
autrement dit l'application \(L\circ s:\ab{1}{n}\rightarrow E\) est croissante. Comme \(s\) est une bijection, notons \(\sigma:=s^{-1}\) la permutation réciproque. On peut alors réécrire \((\ref{eq:omega2})\) :
\begin{equation}\label{eq:omega3}
\forall (i,j)\in\ab{1}{n}^2,\quad \sigma(i)\leqslant \sigma(j)\Rightarrow L[i]\preccurlyeq L[j].
\end{equation}
Démontrez la deuxième partie du lemme sur l'implication réciproque.
Soit \(E=\{x_1,x_2,\ldots,x_n\}\) un ensemble totalement ordonné. Montrez qu'il existe une unique bijection croissante entre l'ensemble \(E\) et l'ensemble \(\{1,\ldots,n\}\) muni de la relation d'ordre naturel. Démontrez qu'une liste \(L\) d'éléments d'un ensemble \(E\) totalement ordonné est triée si et seulement si \(L\) est une application croissante.
Pour ne pas compliquer inutilement l'exposé nous pouvons légitimement nous limiter à l'étude des listes \(L\) qui sont des permutations de \({\frak S}_n\) où \(n\) désigne la taille de la liste \(L\).
Arbre de décision
À chaque fois qu'une structure de contrôle est rencontrée dans l'exécution d'un algorithme, son exécution peut être déroutée vers autant de blocs d'instructions différents que la structure en gère (si/alors/sinon, tant que, switch, etc.) Par analogie avec le comportement humain, on dit que l'algorithme prend une décision. On modélise l'ensemble des conditions rencontrées par un algorithme ainsi que les décisions qui en découlent par un arbre enraciné appelé arbre de décision. Chaque condition est représentée par un nœud auquel on associe autant de branches qu'il y a de décisions possibles. La racine de l'arbre contient la première condition rencontrée. Dans le cas particulier d'un algorithme de tri comparatif, une décision est prise en fonction du résultat d'une comparaison, il s'agit donc d'un arbre de décision binaire :
la branche gauche signifie que le résultat de la comparaison est négatif ;
la branche droite signifie que le résultat de la comparaison est positif.
Le choix des associationsgauche/négatif et droit/positif est bien sûr arbitraire.
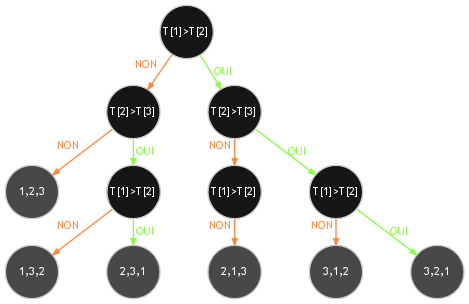
Observons les différentes comparaisons \(T[i] > T[i + 1]\) effectuées par l'algorithme TriBulles du tri à bulles ainsi que l'évolution du tableau pour les \(3!=6\) instances de taille \(n=3\) :
Nous indiquons dans chaque nœud interne de l'arbre de décision, la comparaison \(T[i] > T[i + 1]\) réalisée et l'instance traitée par l'algorithme dans chacune des 6 feuilles. Le chemin qui mène de la racine à une feuille/instance permet de suivre les différentes comparaisons effectuées pour la trier.
Arbre de décision de l'algorithme TriBulles pour les instances de taille 3.
Construisez l'arbre de décision du tri par insertion TriInsertion et du tri par sélection TriSélection pour \(n=3\).
Borne inférieure sur la complexité
C'est l'arbre de décision associé à un tri qui va nous permettre d'établir une borne sur la complexité.
L'arbre de décision d'un algorithme de tri comparatif appliqué à des permutations \(L\) du groupe \({\frak S}_n\) contient \(n!\) feuilles.
La liste \(L\) de taille \(n\) à trier est confondue avec la permutation sous jacente de \(\frak S_n\). Un algorithme de tri doit être en mesure trier toutes les permutations \(L\) possibles soit \(n!\) permutations distinctes. Montrons que deux permutations distinctes ont nécessairement des feuilles distinctes dans l'arbre de décision. Que l'algorithme s'effectue in situ ou non, si l'on note \(L\) la liste d'entrée et \(I\) la liste de sortie triée, autrement dit l'identité de \({\frak S}_n,\) l'algorithme construit implicitement la permutation inverse de \(L\) i.e. la permutation \(\sigma\in\frak S_n\) telle que \(\sigma\circ L = I\). Si l'on suppose que deux listes \(L\) et \(L'\) sont représentées par la même feuille dans l'arbre de décision, cela signifie que les instructions exécutées par l'algorithme sont strictement identiques dans les deux cas, autrement dit qu'il réalise la même permutation \(\sigma\). On a par conséquent \(\sigma\circ L=I=\sigma\circ L'\) et la permutation \(\sigma\) étant une bijection on en conclut que \(L=L'\).
La complexité dans le pire des cas d'un algorithme de tri comparatif est en \(\Omega(n\log n)\) où \(n\) désigne le nombre de valeurs à trier dans un ensemble totalement ordonné.
Le nombre de comparaisons effectuées pour trier une liste \(L\) de taille \(n\) est par construction la longueur (i.e. le nombre d'arcs) du chemin qui relie la racine de l'arbre de décision à la feuille associée à \(L\). Le pire des cas pour un algorithme de tri comparatif correspond donc au chemin le plus long dans son arbre de décision, c'est-à-dire à la hauteur \(h\) de l'arbre. Nous devons donc évaluer quelle est la longueur minimale de ce chemin. Autrement dit, il faut construire un arbre contenant au moins \(n!\) feuilles et dont la hauteur \(h(n)\) soit minimale. Un arbre binaire de hauteur \(h\) contient au plus \(2^h\) feuilles, maximum atteint par un arbre binaire équilibré et complet. La hauteur \(h(n)\) doit donc satisfaire l'inégalité suivante~:
\begin{equation}\label{eqtricom1}
2^{h(n)}\geqslant n!
\end{equation}
soit
\begin{equation}\label{eqtricom2}
h(n)\geqslant \sum_{i=1}^n\log_2 i.
\end{equation}
On minore classiquement cette somme par une intégrale en rappelant que la primitive de \(\ln x\) est \(x\,\ln x -x\) ou en faisant une intégration par parties pour le retrouver ::
\begin{align*}
\sum_{i=1}^{n}\log_2 i
&=\sum_{i=2}^{n}\log_2 i\\
&\geqslant \frac{1}{\ln 2}\int_{1}^{n}\ln x\, dx\\
&=\frac{1}{\ln 2}\left[x\ln x -x\right]_{1}^{n}\\
&\geqslant n\log_2 n-\frac{n}{\ln 2}
\end{align*}
Ce qui achève la démonstration.
Si l'on veut faire mieux qu'une complexité linéarithmique, il est donc indispensable d'envisager le tri sans s'appuyer sur des comparaisons. Nous verrons dans le chapitre tri par dénombrement et par répartition que l'on peut parfois trier des données avec une complexité linéaire.
Démontrez qu'un arbre binaire enraciné de hauteur \(h\) contient au plus \(2^h\) feuilles.