La notion de graphe a été abordée en 1ère année et ses nombreuses déclinaisons s'avèrent d'une très grande richesse, à la fois comme modèles et comme outils d'étude en algorithmique. Elle fait l'objet d'une théorie à part entière, la théorie des graphes.
Dans un arc \((x,y),\) le sommet \(y\) est appelé le successeur de \(x\) et le sommet \(x\) le prédécesseur de \(y\). On note \(\Gamma\) la correspondance \((X,U,X)\) et pour tout sommet \(x\in X\) du graphe, on écrit \(\Gamma(x)\) (resp. \(\Gamma^{-1}(x)\)) plutôt que \(\Gamma(\{x\})\) (resp. \(\Gamma^{-1}(\{x\})\)) l'ensemble des successeurs (resp. prédécesseurs) de \(x\). Un arc \((x,x)\) est qualifié de boucle. Les propriétés d'un graphe orienté sont héritées de celles de la relation binaire qui lui est associée : réflexivité, symétrie, transitivité, etc. Si l'orientation n'a pas d'importance, on remplace généralement les couples par des paires \(\{x,y\}\) ou des singletons \(\{x\}\) pour les boucles, i.e. \(U\subseteq({\mathscr P}_2(X)\cup{\mathscr P}_1(X))\). On parle alors d'arête au lieu d'arc et le graphe est dit non orienté.
Dans un graphe orienté (resp. non orienté), une séquence \(x_1,\, x_2,\ldots,\, x_n\) de \(n\) sommets telle que \[ \forall i\in\ab{1}{n-1}\quad (x_i,x_{i+1})\in U \] est appelée un chemin (resp. une chaîne) reliant \(x_1\) à \(x_n\) dont la longueur est le nombre d'arcs/arêtes, donc \(n-1.\) Si la séquence commence et se termine par le même sommet, i.e. \(x_1=x_n,\) on parle de circuit (resp. de cycle). Un chemin/chaîne qui passe exactement une fois par chaque arc/arête est appelé chemin eulérien/chaîne eulérienne. Un chemin/chaîne qui passe exactement une fois par chaque sommet est appelé chemin hamiltonien/chaîne hamiltonienne.
Un graphe est dit connexe si pour tout couple de sommets du graphe, il existe au moins une chaîne qui les relie (on ne tient compte que de la connexion, pas du sens des flèches). Un sous-graphe d'un graphe \(G=(X,U),\) c'est-à-dire la restriction de ses arcs/arêtes à un sous-ensemble \(Y\) de \(X,\) est appelé composante connexe de \(G\) s'il est connexe et maximal : aucune chaîne ne relie un sommet de \(X\setminus Y\) à un sommet de \(Y\). Un sous-graphe est appelé composante fortement connexe si pour tout couple de sommets \((x,y)\), il existe un chemin qui relie \(x\) à \(y\) (là on tient compte du sens des flèches). Comme l'orientation n'importe pas dans un graphe non orienté, s'il est connexe il est fortement connexe.
Les successeurs \(\Gamma(x)\) d'un nœud \(x\) sont appelés nœuds fils de \(x\) et ses prédécesseurs \(\Gamma^{-1}(x)\) ses nœuds pères, les successeurs d'un même père sont appelés des nœuds frères. L'arité d'un arbre est la taille de la plus grande fratrie, c'est-à-dire \(\max\{\#\Gamma(x)\mid x\in X\}\).
Un nœud qui n'a pas de fils est appelé une feuille. Un arbre est dit enraciné s'il contient un unique nœud sans prédécesseur, qu'on appelle alors racine de l'arbre.
La profondeur d'un nœud ou la hauteur d'un nœud (tout est question de point de vue…) est la longueur du chemin qui le relie à la racine de l'arbre. La profondeur d'un arbre est la profondeur maximale d'une feuille. Le nombre de nœuds à la profondeur \(p\) est au plus \(q^p\) si l'arbre est d'arité \(q\). Un arbre de profondeur \(p\) est dit équilibré si tout nœud de profondeur \(k\) tel que \(k < p - 1\) a exactement \(q^k\) fils. Un arbre peut être muni d'une valuation de ses nœuds (et/ou de ses arcs), c'est-à-dire d'une application \(\nu:X\to V\) (et/ou \(\mu:U\to V\)) où \(V\) est un ensemble ordonné (le plus souvent \(V=\R\)).
On cherche à nouveau à trier les valeurs d'un tableau/liste dans l'ordre croissant. Le tri par tas repose sur des échanges de valeurs des nœuds d'un arbre binaire valué. Bien que les arbres soient indispensables pour comprendre ces manipulations, ce tri n'utilise jamais de structure d'arbre pour son implantation, mais opère in situ, c'est-à-dire sur le tableau/liste fourni(e) en entrée. Par conséquent, la structure à trier est plutôt envisagée comme une structure statique de tableau.
L'algorithme s'appuie sur une propriété particulière de certains tableaux appelés tas. Pour comprendre ce qu'est un tas, il faut introduire la notion d'arbre partiellement ordonné (en résumé APO).
Un arbre binaire est donc partiellement ordonné si la valuation de chaque nœud est supérieure à celle de ses fils s'ils existent. Notons que ce choix est arbitraire, on peut évidemment considérer des tas pour l'ordre inverse, la valuation du père étant alors inférieure à celles de ses fils. Dans la suite pour alléger les écritures, on confondra souvent un nœud \(x\) avec sa valuation \(\nu(x)\).
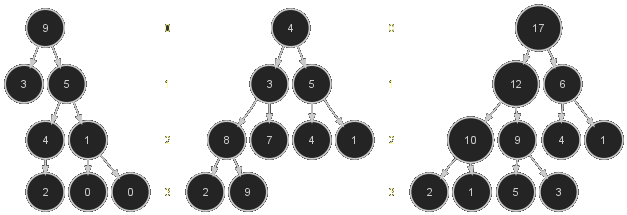
Dans les arbres enracinés ci-dessous, l'arbre binaire à gauche est partiellement ordonné mais pas équilibré, l'arbre central est équilibré mais n'est pas partiellement ordonné, tandis que l'arbre à droite est à la fois équilibré et partiellement ordonné. Les nombres entre les arbres indiquent la profondeur des nœuds dans l'arbre.
Les arbres sont très souvent représentés à l'envers (racine en haut et feuilles en bas) à cause du sens de lecture qui suit la chronologie de leur construction, celle-ci commençant très souvent par la racine (pour le modèle abstrait tout au moins). C'est ce qui explique le double vocabulaire hauteur/profondeur.
Quand on dispose d'un arbre équilibré valué, on peut le représenter très simplement avec une structure de liste/tableau et réciproquement, il suffit de ranger les valuations des nœuds dans la liste en suivant l'ordre naturel de lecture, de la gauche vers la droite et de haut en bas. Ainsi le tableau associé à l'arbre de droite de la figure ci-dessus est
\begin{equation}\label{ex:tas} T = [17,12,6,10,9,4,1,2,1,5,3] \end{equation}Autrement dit, \(T[i]:=\nu(i)\) pour l'ensemble des sommets \(X=\ab{1}{n}.\)
Le tableau en (\ref{ex:tas}) est donc un tas. La propriété APO a pour conséquence immédiate que la racine de l'arbre contient la valeur la plus grande, autrement dit la première valeur du tableau est la plus grande.
Cette dernière propriété est la clef du fonctionnement du tri par tas. Ce tri ne manipule en réalité qu'une structure de tableau/liste et jamais de structure d'arbre qui ne sert qu'à comprendre les mécanismes de ce tri. Nous allons tout d'abord décrire comment l'algorithme trie un tas. Bien entendu, tous les tableaux ne sont pas des tas, mais nous verrons comment transformer un tableau quelconque en tas avec l'algorithme Entasser un peu plus bas.
Le principe du tri est simple et élégant. La plus grande valeur, \(17\) dans notre exemple, étant placée en tête du tas d'après le lemme précédent, il suffit de l'échanger avec la dernière valeur du tableau, ici \(3,\) pour qu'elle soit définitivement rangée, comme le fait par exemple le TriSélection. C'est ce que montre l'arbre à gauche ci-dessous pour le tas \((\ref{ex:tas})\). Après cette transposition, l'arbre n'est plus nécessairement apo (sauf si la valeur qui était dans la dernière cellule du tableau avant l'échange se trouvait être justement la seconde plus grande valeur du tableau).
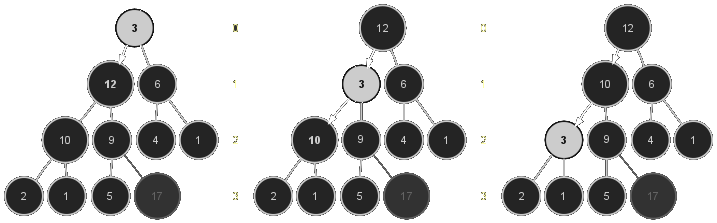
Pour restaurer la propriété APO à la racine, il suffit d'échanger sa valeur avec celle du fils qui contient la plus grande, ici \(12\) (cf. arbre au centre de la figure). On repousse alors le problème sur la racine du sous-arbre où l'on a fait l'échange, ici le sous-arbre gauche, et il suffit de recommencer l'opération jusqu'à ce que la propriété soit rétablie, au pire en rencontrant une feuille. Dans notre exemple, la valeur 3 s'arrête dans sa descente après la transposition avec \(10\) puisque la propriété apo est alors vérifiée. L'opération qui consiste à faire descendre la valeur de la racine dans l'arbre doit bien entendu être réalisée sur le tableau T. Le lecteur démontrera le lemme suivant :
L'algorithme Tamiser a trois paramètres, le tableau, l'index du père et l'index de la dernière cellule à considérer dans le tableau. Les premières instructions #13 à #15 servent à trouver la valeur ifils de l'indice du fils avec lequel il faudra faire l'échange, c'est-à-dire celui qui a la plus grande valuation.
ALGORITHME Tamiser(@T,ipere,ifin):booléen
DONNEES
T: tableau de valeurs
ipere,ifin: entiers
VARIABLES
ifils: entier
ech, continuer: booléens
DEBUT
continuer ← VRAI
ech ← FAUX
TQ continuer FAIRE
continuer ← FAUX
ifils ← 2 * ipere
SI ((ifils < ifin) ET (T[ifils+1] > T[ifils])) ALORS
ifils ← ifils + 1
FSI
SI ((ifils ≤ ifin) ET (T[ipere] < T[ifils])) ALORS
Echanger(T,ipere,ifils)
ech ← VRAI
continuer ← VRAI
ipere ← ifils
FSI
FTQ
RENVOYER ech
FIN
Le paramètre ipere permet d'appliquer l'algorithme à un sous-arbre de racine ipere et le paramètre ifils est nécessaire pour arrêter le processus de tamisage avant la fin du tableau/arbre au fur et à mesure que les valeurs maximales auront été placées en fin de tableau lors du tri. À titre indicatif, l'algorithme renvoie un booléen pour signifier qu'il y a eu échange(s) ou non. La preuve du résultat suivant qui justifie la validité de l'algorithme est laissée au lecteur.
Le tri d'un tas coule alors de source, l'arbre ayant retrouvé sa propriété APO, la plus grande valeur du tableau est de nouveau en première position et il suffit de l'échanger avec l'avant dernière valeur et de recommencer le processus jusqu'à ce que toutes les plus grandes valeurs aient été rangées à la fin du tableau.
Supposons que l'on dispose d'un algorithme Entasser (nous le décrirons plus loin) qui transforme un tableau quelconque en tas, le tri s'écrit facilement :
ALGORITHME TriTas(@T)
DONNEES
T: tableau de valeurs
VARIABLES
ifin: entier
DEBUT
Entasser(T)
k ← #T
TQ (k > 1) FAIRE
Echanger(T, 1, ifin)
ifin ← ifin - 1
Tamiser(T, 1, ifin)
FTQ
FIN
Il reste à présent à convertir un tableau quelconque \(T\) en tas. Pour cela, il faut rétablir la propriété \((\ref{eq:apo})\) en chaque nœud où elle fait défaut. C'est bien sûr l'algorithme Tamiser qui va être appliqué sur les nœuds en question. On pourrait être tenté de traiter les nœuds dans l'ordre de lecture, donc en commençant par la racine de l'arbre, mais le tableau \(T=[1,3,2,4]\) est transformé en \(T=[3,4,2,1]\) par l'algorithme et ce n'est pas un tas. Le lemme 8 indique comment procéder. En commençant par le bas, on s'assure ainsi que les sous-arbres gauche et droit sont toujours APO avant d'appliquer l'algorithme. Comme les feuilles sont toujours APO, il est inutile de les tester. Reste alors à déterminer par quel nœud commencer ?
ALGORITHME Entasser(@T)
DONNEES
T: tableau de valeurs
VARIABLES
ipere, ifin: entiers
DEBUT
ifin ← #T
ipere ← ifin / 2
TQ (ipere > 0) FAIRE
Tamiser(T, ipere, ifin)
ipere ← ipere - 1
FTQ
FIN
L'exécution de l'algorithme Tamiser est visualisée dans l'arbre binaire associé au tableau saisi ci-dessous en coloriant les nœuds de l'arbre. Le nœud père en jaune est comparé au plus grand de ses fils, en vert si la propriété apo est satisfaite, en rouge si elle est violée.
Une fois que le tableau \(T\) est devenu un tas, la racine et le dernier nœud qui seront échangés par l'algorithme TriTas sont cerclés de bleu. NB. Pour que l'affichage reste lisible, le nombre de valeurs est limité à 63.
Nous allons estimer la complexité en calculant le nombre de fois où l'on teste la propriété APO en un nœud, qui est la clef du fonctionnement des deux algorithmes Entasser et TriTas. Ce nombre de tests permet aisément de déterminer le coût global puisque si la condition apo est satisfaite il n'y a rien à faire, sinon il faut échanger un père avec l'un de ses fils, mais dans les deux cas le coût est constant. Donc chaque test de condition apo a une complexité en \(\Theta(1)\).
En notant \(n:=\#T\) et \(\tau(i)\) le nombre de tests apo réalisés par Tamiser(T,i,n) dans la boucle, le nombre total de tests est \[ \sum_{i=\lfloor\frac{n}{2}\rfloor}^{1}\tau(i). \] Dans le meilleur des cas le tableau est déjà un tas et un seul test a lieu pour chacun des \(\lfloor\frac{n}{2}\rfloor\) nœuds à traiter, i.e. \(\tau(i)=1,\) on a donc \[ \check{T}_{\text{Entasser}}(n)=\Theta(n). \]
Mais la définition d'une partie entière nous donne les inégalités \[ \lfloor \log_2(i)\rfloor\leqslant \log_2(i) \lt \lfloor\log_2(i)\rfloor + 1, \] et on déduit \(-\lfloor \log_2(i)\rfloor \lt 1-(\log_2(i)) \) de la dernière pour obtenir \begin{align} \widehat{T}_{\text{Entasser}}\;(n) \tag{} &\leqslant {m} (h+1)+\sum_{i=1}^{{m}}(1-(\log_2(i)))\\ \tag{} &\leqslant {m} (\log_2(n)+2)-\sum_{i=1}^{{m}}\log_2(i)\\ &\leqslant {m}\log_2(n) + n-{\color{yellow}\sum_{i=1}^{{m}}\log_2(i)} \label{eqtas}\quad\text{car}\ 2{m}\leqslant n. \end{align} Classiquement, on minore la somme par une intégrale en se rappelant qu'une primitive de \(\ln x\) est \(x\,\ln x -x\) : \begin{align*} {\color{yellow}\sum_{i=1}^{{m}}\log_2(i)}= \sum_{i=2}^{{m}}\log_2(i) &\geqslant \frac{1}{\ln(2)}\int_{1}^{{m}}\ln(x)\, dx\\ &\geqslant \frac{1}{\ln(2)}\left[x\ln(x) -x\right]_{1}^{{m}}\\ &\geqslant \frac{1}{\ln(2)}\left({m}\ln({m})-{m}+1\right)\\ &\geqslant {m} \log_2({m}) - \frac{1}{\ln(2)}({m}-1)\\ &\geqslant {m} \log_2({m}) - 2({m}-1)\quad\text{car}\ 1/(\ln(2))<2 \\ &\geqslant {m} \log_2({m}) - n \end{align*} En injectant ce résultat dans (\ref{eqtas}), on arrive à : \begin{align*} \widehat{T}_{\text{Entasser}}\;(n) &\leqslant {m}\log_2(n) + n-\color{yellow}{{m} \log_2{m} +n}\\ &\leqslant {m}\left(\log_2(n)-\log_2({m}) \right)+2n\\ &\leqslant \underbrace{\lfloor\frac{n}{2}\rfloor\left(\log_2n-\log_2\lfloor\frac{n}{2}\rfloor \right)+2n}_{f(n)} \end{align*}
Si \(n\) est pair, disons \(n=2k,\) on vérifie que \(f(2k)=5k\) et donc \(f(n)=\frac{3n}{2}\). Comme la fonction \(f\) est croissante, on a \(f(n)\leqslant f(n+1)\) et si \(n\) est impair, disons \(n=2k+1,\) alors \(f(n)\leqslant 5(k+1)=\frac{5}{2}(n+1).\) On en conclut que \[\widehat{T}_{\text{Entasser}}(n)=O(n).\]
L'analyse du meilleur des cas et du cas moyen du tri par tas sont très difficiles et n'ont été obtenus qu'en 1992 par R. Shaeffer et R. Sedgewick et publiés dans The analysis of heapsort, Journal of Algorithms, Vol. 15, #1, pp. 76-100, 1993. Dans les deux cas la complexité est en \(\Theta(n\log n)\) mais le cas moyen est 2 fois plus coûteux que le meilleur des cas.
Reste le pire des cas qui relativement facile à majorer. Nous avons vu que la transformation d'un tableau en tas a un coût en \(\Theta(n)\) dans le pire des cas. Il reste donc à établir le coût du tri d'un tas que nous allons estimer via le nombre d'échanges réalisés entre nœuds de l'arbre. Il y a deux types d'échanges :
Commençons par ceux du premier type : il y en a exactement \(n-1\) car la dernière valeur à trier est \(1\) et elle est à sa place à la racine de l'arbre. Comptons à présent les échanges réalisés par les tamisages.
Après chaque échange du type 1, il faut restaurer la propriété apo. On sait que la nouvelle valeur à la racine peut descendre dans le pire des cas jusqu'à la profondeur de l'arbre \(p:=\lfloor \log_2(n)\rfloor\), ce qui nous donne immédiatement une majoration grossière de \(n\lfloor\log_2(n)\rfloor\). On peut néanmoins faire un calcul (un peu) plus fin.
Par construction, l'arbre binaire est parfaitement équilibré, il y a donc exactement \(2^k\) nœuds à la profondeur \(k\) pour tout \(k\in\ab{0}{p-1}.\) Seule la profondeur maximale \(p\) ne contient pas nécessairement l'intégralité des \(2^p\) nœuds, mais il est facile de calculer combien en dénombrant le nombre total de nœuds aux profondeurs inférieures, c'est la somme de la série géométrique de terme général \(2^i\) : \begin{align*} \sum_{i=0}^k2^i=2^{k+1}-1 \end{align*} Par conséquent, il reste \(\color{#88F}n-(2^p-1)\) nœuds à la profondeur maximale \(p\).
Ceci nous permet de majorer la longueur totale \(\ell(n)\) que peuvent parcourir les \(n-1\) valeurs à la racine lors des \(n-1\) appels à l'algorithme Tamiser (le premier appel se fait après l'échange \(T[1]\rightleftharpoons T[n]\)). En retirant ce cas particulier du calcul, il reste donc \(\color{#88F}n-2^p\) valeurs qui peuvent parcourir un chemin de longueur maximale \(p\) et exactement \(2^k\) valeurs qui peuvent parcourir un chemin de longueur \(k\) pour chacune des profondeurs \(k\in\ab{0}{p-1}\) :
\begin{equation} \ell(n) =\left({\color{orange}\sum_{k=0}^{p-1}k\,2^k}\right)+p({\color{#88F}n-2^p})\\ \end{equation}Ce lemme nous permet de calculer la somme ci-dessus pour \(X:=2\) et qui vaut \({\color{orange}p2^p-2^{p+1}+2}.\) Donc
\begin{equation} \label{eq:ell} \ell(n)=pn-2^{p+1}+2 \end{equation}Il ne reste qu'à remplacer \(p\) par \(\lfloor\log_2(n)\rfloor\) : \begin{align*} \ell(n)&=\lfloor\log_2(n)\rfloor\, n-2^{\lfloor\log_2(n)\rfloor+1}+2 \end{align*}
Mais pour tout réel \(x\), on a \(\lfloor x\rfloor\leqslant x\lt \lfloor x\rfloor+1,\) donc \begin{align*} \ell(n)&\leqslant n\log_2(n)-2^{\log_2(n)}+2\\ &\leqslant n\log_2(n)-n+2 \end{align*}
L'addition du coût \(\Theta(n)\) de la transformation en tas et des \(n-1\) échanges de type 1 ne changent pas la classe de complexité :
Il faut bien noter qu'il s'agit d'une majoration, la construction d'une instance qui cumulerait la longueur totale \(\ell(n)\) calculée en \((\ref{eq:ell})\) est un problème difficile.
Indication : reprenez la fonction uint *GenPerm(uint n) qui renvoie une permutation de taille \(n\) dont les valeurs ont été tirées au hasard. Reprenez cette suggestion pour engendrer une permutation aléatoire.