
C'est l'étude des fonctions de complexité des algorithmes qui nous amène à introduire des outils d'analyse efficaces et c'est leur comportement asymptotique qui nous éclaire sur les temps de calculs que l'on peut espérer une fois qu'ils seront implantés sur des ordinateurs. Plutôt que calculer l'expression exacte de la fonction de complexité, qui reste souvent hors de portée, on cherche surtout à déterminer son comportement général. La fonction est-elle de type logarithmique, linéaire, linéarithmique, quadratique, exponentielle, etc. ?
Le domaine de définition de ces fonctions est tout ou partie de l'ensemble des entiers naturels \({\mathbb N}\). Cependant, pour simplifier des calculs ou pour certaines estimations, on considèrera souvent des fonctions sur le domaine réel. On note dans toute la suite \({\mathscr F}\) l'ensemble des fonctions de \({\mathbb N}\) dans \({\mathbb R}\).
Les notations asymptotiques utilisées pour mesurer et comparer la grandeur des fonctions que nous allons voir (ou revoir) sont des extensions des notations de Landau \(o\) et \(O\) bien connues de l'étudiant dans le cadre des développements limités. C'est D. Knuth qui a largement popularisé les notations désormais classiques \(\Omega,\) \(\Theta,\) \(O\), pour faire le ménage dans le calcul de complexité.
Notons immédiatement que pour l'analyse de certains algorithmes, il peut être intéressant d'étudier des fonctions à plusieurs variables entières, chaque variable correspondant à la taille d'une partie des données en entrée. Par exemple l'algorithme du calcul du produit de deux entiers reçoit en entrée deux séquences de longueurs arbitraires \(n\) et \(m\) (les chiffres des deux opérandes dans une base fixée), on manipule donc des fonctions à deux variables \(f(n,m)\) et les notations asymptotiques sont similaires au cas à une variable.
Que disent ces définitions ? Une fonction \(f\in O(g),\) qu'on lit \(f\) est en grand omicron de \(g\), est majorée par une constante fois la fonction \(g\) à partir d'un certain rang \(\color{darkcyan}N\). Une fonction \(f\in \Omega(g),\) qu'on lit \(f\) est en grand omega de \(g\), est minorée par une constante fois la fonction \(g\) à partir d'un certain rang \(N\). La notation grand Omicron est strictement identique à la notation grand \(O\) de Landau, on dira donc indifféremment \(f\) est en grand omicron de \(g\) ou \(f\) est en grand O de \(g\).
Une fonction peut être à la fois majorée et minorée par des facteurs d'une fonction de référence \(g\) à partir d'un certain rang, ce que l'on résume par :
Encore une fois, on écrit abusivement \(f=\Theta(g)\) au lieu de \(f\in \Theta(g)\) et on lit \(f\) est en grand thêta de \(g.\) Cela signifie que l'ensemble \(\Theta(g(n))\) contient toutes les fonctions que l'on peut coincer entre deux fonctions homothétiques à \(g\) à partir d'un certain rang. Autrement dit pour \(n\) suffisamment grand, les fonctions de \(\Theta(g(n))\) se comportent comme la fonction \(g\) à une constante multiplicative près.
L'expression algébrique d'une fonction et quelques connaissances sur la croissance des fonctions réelles suffisent parfois à mettre en évidence qu'une majoration est grossière, par exemple quand on affirme que la fonction \(n\mapsto 2n+1\) est en \(O(n^3)\). Ce n'est pas la définition de la notation \(O\) qui nous permet d'affirmer que cette estimation est grossière, mais la connaissance de la croissance des fonctions monomiales. Ainsi l'écriture \(f=O(g)\) ne précise pas si \(f\) croit beaucoup moins vite que toute constante fois \(g\) asymptotiquement ou si \(f\) s'en approche. La notation petit \(o\) répond partiellement à cette question, quand on écrit \(f=o(g)\) on signifie que :
\[\lim_{n\rightarrow+\infty} \frac{f(n)}{g(n)}=0\]La notation \(\omega(g)\) est à \(o(g)\) ce que \(\Omega(g)\) est à \(O(g)\) :
Sans une lecture attentive, on pourrait croire, à tort, qu'il s'agit des mêmes définitions que celles des notations \(O\) et \(\Omega,\) mais le quantificateur universel \(\color{yellow}\forall\) remplace ici le quantificateur existentiel \(\color{#6464FF}\exists\). Il faut entendre par \({\color{yellow}\forall}c\in\R_+\), que la constante peut être choisie aussi petite que l'on veut, ce qui revient à écraser la courbe représentative de \(g\) sur l'axe des abscisses.
Dans l'estimation de la complexité d'un algorithme, le graal est d'être en mesure de connaître le comportement asymptotique de la fonction de complexité et pas uniquement à une constante multiplicative près. Si l'on définissait l'équivalence d'une fonction \(f\) à une fonction de référence \(g\) via le comportement asymptotique de leur différence \(|f(n)-g(n)|\) que l'on voudrait aussi faible que possible, \(n\mapsto n^2+n\) ne serait pas équivalente à \(n\mapsto n^2\) car leur différence \(n\mapsto n\) diverge alors que la fonction \(n\mapsto n\) devient manifestement négligeable devant la fonction \(n\mapsto n^2\) quand \(n\) est grand. Il est plus judicieux de définir l'équivalence entre \(f\) et \(g\) à l'aide de la limite :
\begin{equation*} \lim_{n\rightarrow+\infty}\frac{f(n)}{g(n)} = 1. \end{equation*}qui est traduite en \((\ref{eq:equivqasympt})\) dans la définition
Un bon moyen mnémotechnique (attention, en toute rigueur c'est faux) pour se souvenir de la signification des notations asymptotiques est résumé par : \begin{align*} f=O(g)\ &\Leftrightarrow\ f\leqslant g & f=o(g)\;\,\ &\Leftrightarrow\ f \lt g\\ f=\Omega(g)\ &\Leftrightarrow\ f\geqslant g& f=\omega(g)\ &\Leftrightarrow\ f \gt g\\ f=\Theta(g)\ &\Leftrightarrow\ f\approx g & f\sim g\ \quad &\Leftrightarrow\ f= g \\ \end{align*}
Pour conclure cette section, nous pouvons noter que l'emploi des notations asymptotiques permet de se débarrasser d'une part des perturbations de la fonction de complexité pour les petites tailles des entrées avec l'introduction du rang \(N,\) et d'autre part du facteur constant de l'expression de cette fonction. La contrepartie de cette souplesse apparaît surtout sur le facteur constant que l'on appelle facteur caché (ou constante cachée). Imaginons que la fonction de complexité d'un algorithme \(A\) soit \(T_A(n)=\frac{1}{8}n^2-64n+8\) et celle d'un algorithme \(B\) soit \(T_B(n)=1789n+1968,\) les deux résolvant le même problème. Avec les écritures asymptotiques, on écrira \[T_A(n)=\Theta(n^2)\qquad T_B(n)=\Theta(n).\] et on privilégiera très logiquement l'algorithme \(B\) à l'algorithme \(A\) ! Pourtant l'algorithme \(B\) ne devient plus performant que l'algorithme \(A\) qu'à partir de la valeur \(n=14\,825.\) Il faut donc en conclure que l'analyse asymptotique des algorithmes est… asymptotique ! Autrement dit, pour des réalisations effectives d'algorithmes, le facteur caché peut avoir une certaine importance et pourra même valider un algorithme a priori mauvais.
Les algorithmes que nous allons étudier contiennent systématiquement des boucles (ou des appels récursifs), les calculs de complexité font donc apparaître des quantités qu'il faudra sommer, à savoir le nombre d'instructions que la machine ram doit décoder à chaque passage dans la boucle. Que ce nombre d'instructions varie ou non, ses valeurs successives constituent une suite numérique.
Soit \((u_n)_{n\in{\mathbb N}}\) une suite numérique (ici des nombres réels). On rappelle que la somme \begin{equation} S_n:=\sum_{i=0}^nu_i. \end{equation} des \(n+1\) premiers termes de la suite \((u_n)\) définit elle-même une suite \((S_n)_{n\in{\mathbb N}}\) de nombres réels qu'on appelle la série de terme général \(u_n\). Attention au vocabulaire ! En toute rigueur le terme général de la série \((S_n)_{n\in{\mathbb N}}\) devrait faire référence à \(S_n\) (qui est une somme partielle de la série \((S_n)_{n\in{\mathbb N}}\)) puisqu'il s'agit d'une suite, on fait pourtant référence au terme général \(u_n\) de la suite associée.
On dit que \((S_n)_{n\in{\mathbb N}}\) est une série convergente si c'est une suite convergente, i.e. s'il existe un nombre réel \(l\) appelé la limite de la série \((S_n)_{n\in{\mathbb N}},\) tel que \[\forall \varepsilon \gt 0\ \ \exists N\in{\N}\ \ \forall n\in\N\ \ (n\geqslant N\then|S_n-l|<\varepsilon)\]
Dans le cas contraire, c'est une série divergente. Plus généralement quand une série de terme général \(u_n\) est convergente on peut noter sa limite \begin{equation} \label{serie} \sum_{i=0}^\infty u_i. \end{equation}
Une série \((S_n)_{n\in{\mathbb N}}\) de terme général \(u_n\) est dite absolument convergente si la série de terme général \(|u_n|\) est convergente. Les deux écritures \begin{equation} \sum_{i=0}^\infty u_i,\quad\text{et}\quad \sum_{i\in{\mathbb N}}u_i \end{equation} ne sont pas équivalentes. La première indique explicitement l'ordre dans lequel on rajoute les termes de la suite dans la somme partielle, et ceci a une importance capitale pour la convergence ou la divergence de la série. L'ordre n'est pas spécifié dans la seconde ce qui laisse entendre qu'il ne change rien à la limite — ce qui est faux. Considérons par exemple la suite de terme général \begin{equation} \label{eq:defseq} u_i=\begin{cases} 0,&\text{si \(i\) est pair}.\\ 1,&\text{si \(i\) est impair}. \end{cases} \end{equation}
autrement dit, il s'agit de la suite alternée \(010101\ldots\) Dans ce cas précis, il est évident que si l'on décompose la somme sur les indices pairs et impairs, en commençant la sommation sur les indices pairs, on converge vers \(0,\) alors que la série diverge. En revanche, pour une série absolument convergente, il y a égalité et l'ordre de la sommation n'a pas d'incidence sur le résultat, on réservera donc la seconde écriture aux séries absolument convergentes.
La propriété de linéarité pour des sommes finies \begin{equation} \sum_{i=1}^n(\lambda u_i+b_i)=\lambda\sum_{i=1}^nu_i+\sum_{i=1}^nb_i \end{equation} est conservée pour des séries convergentes.
S'il est simple de calculer la somme d'une série arithmétique ou géométrique, il peut être très délicat d'obtenir directement via des formules algébriques l'expression de la somme d'une série arbitraire. On peut parfois deviner l'expression de cette somme sans pour autant être capable de l'obtenir directement. Dans ce cas, on utilise souvent un raisonnement par récurrence pour valider (ou non) l'expression supposée.
Une autre méthode très utile pour approximer une somme consiste à la majorer et/ou minorer par l'intégrale d'une fonction monotone. On est en effet souvent en mesure d'exprimer le nombre d'instructions à décoder dans une boucle à l'aide d'une fonction qui dépend d'un indice de boucle. En algorithmique cette fonction est quasi systématiquement monotone, ce qui explique la popularité de ce procédé de calcul.
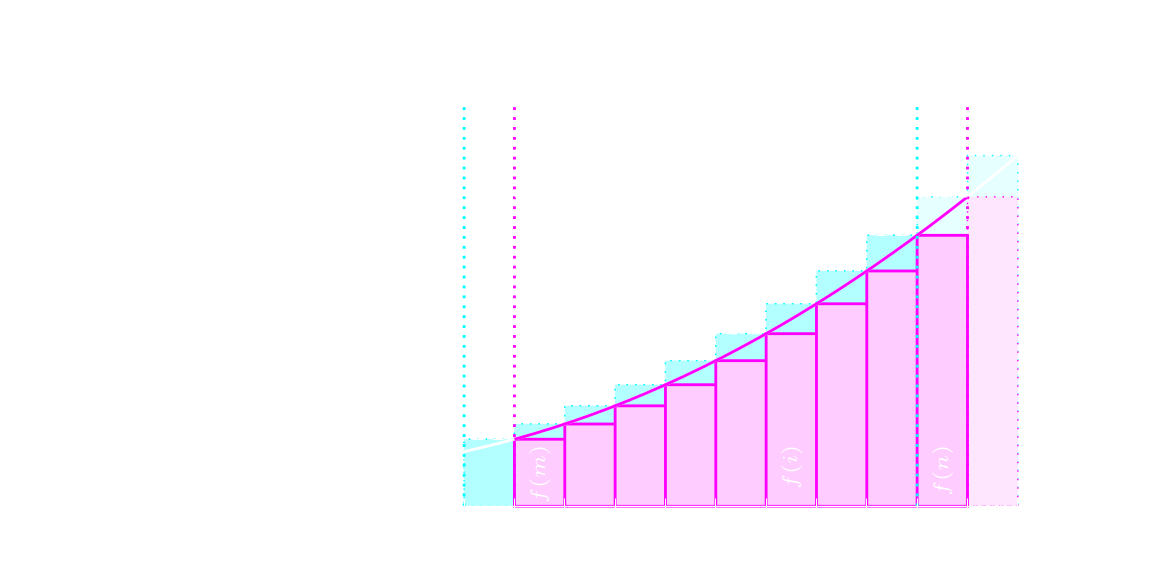
Si on décale tous ces rectangles d'une unité vers la gauche, ils passent alors au-dessus de la courbe et cette fois l'aire de la courbe entre les abscisses \(m-1\) et \(n\) minore la somme.
Notons qu'un algorithme est dit de complexité polynomiale si sa fonction de complexité est majorée par une fonction polynomiale. Ainsi un algorithme de complexité \(O(n\log n)\) est dit de complexité polynomiale car \(\forall n\in{\mathbb N},\ n\log n \leqslant n^2,\) quand bien même la fonction \(n\mapsto n\log n\) n'est pas stricto sensu une fonction polynomiale.
Nous emploierons très souvent les notations asymptotiques dans des calculs comme s'il s'agissait de fonctions. Il est nécessaire de comprendre l'intérêt de cet abus de langage et des pièges qui en découlent. Par exemple, que signifie l'égalité \(O(n^2)+O(n)=O(n^2)\) ? Il faut remplacer dans le calcul chaque notation asymptotique par une fonction quelconque de sa classe. Ici formellement on se donne deux fonctions \(f_1\) et \(f_2\) telles que : \begin{align*} &\exists c_1\in{\mathbb R}_+^*\ \;\exists N_1\in{\mathbb N}\ \;\forall n\geqslant N_1\quad 0\leqslant f_1(n)\leqslant c_1n^2;\\ &\exists c_2\in{\mathbb R}_+^*\ \;\exists N_2\in{\mathbb N}\ \;\forall n\geqslant N_2\quad 0\leqslant f_2(n)\leqslant c_2n. \end{align*} En notant \({\color{yellow}N}:=\max\{N_1,N_2\},\) on en déduit que \begin{align*} \forall n\geqslant N\quad 0\leqslant f_1(n)+f_2(n) &\leqslant c_1n^2+c_2n\\ &\leqslant c_1n^2+c_2n^2\\ &= (c_1+c_2)n^2 \end{align*}
Autrement dit, si on définit \({\color{yellow}c}:=c_1+c_2,\) on vient de prouver que \[\exists {\color{yellow}c}\in{\mathbb R}_+^*\ \;\exists {\color{yellow}N}\in{\mathbb N}\ \;\forall n\geqslant N\quad 0\leqslant f_1(n)+f_2(n)\leqslant cn^2, \] c'est-à-dire \(f_1+f_2=O(n^2)\) ce qui justifie l'écriture \(O(n^2)+O(n)=O(n^2)\). L'exercice suivant montre qu'il faut prendre garde au sens des expressions.La notation \(\Theta(1)\) est particulièrement utile à plus d'un titre. Elle sert intensivement pour le calcul de la complexité d'un algorithme quand celui-ci est décrit dans un langage informel comme celui que nous utilisons. Le calcul de la complexité pour la machine RAM se fait en comptant le nombre d'instructions décodées, en revanche dans notre pseudo-langage algorithmique la notion d'instruction n'est pas précisément définie et nous savons qu'une expression du type \(x\leftarrow 3.12 x-6\) a un coût (en nombre de cycles machine sur un modèle bien réel) bien plus important qu'un incrément \(x \leftarrow x +1\) par exemple. Le coût qui était unitaire dans notre modèle ne l'est plus avec notre pseudo langage.
L'introduction de la notation \(\Theta(1)\) permet de nous affranchir de ce problème si l'on est attentif. En effet, une instruction élementaire dans notre pseudo-langage pourrait être traduite en un groupe d'instructions équivalent pour la machine RAM. Une opération d'incrémentation comme \(x \leftarrow x+1\) est directement traduite par l'instruction
INC xen supposant que \(x\) désigne le registre mémoire associé à la variable \(x,\) et avec les mêmes conventions, une instruction comme \(x \leftarrow x+y\) serait traduite par les trois instructions
LOAD x ADD y STORE xDe la même manière, une instruction conditionnelle comme SI (x+2 < y) ALORS s'écrirait
LOAD x ADD #2 SUB y JUML adresseDans les trois cas, le nombre d'instructions est borné inférieurement et supérieurement par deux constantes, ici \(1\) et \(4\). On peut donc dire ici qu'une instruction a un coût de \(\Theta(1)\) et on ne se préoccupe plus de l'inflation engendrée par la traduction. Bien entendu la diversité des instructions possibles en pseudo-langage algorithmique et l'absence de grammaire formelle nous empêche d'étudier cette inflation de manière exhaustive, mais nous serons en mesure de déterminer aisément si elles ont un coût en \(\Theta(1)\) ou non.